搜索到
47
篇与
的结果
-
 DW AXI DMAC简单理解 DMAC简介DMAC(AXI Direct Memory Access Controller)是一种高速、高吞吐量的通用 DMA 控制器,用于在系统内存和其他外设之间传输数据。AXI 表示 Advanced eXtensible Interface,是一种高性能、低延迟的总线协议,用于连接不同的硬件模块,例如处理器、DMA 控制器、存储器、外设等AXI DMAC 是一种特定于 AXI 总线的 DMA 控制器,支持高带宽、直接内存访问。它可以在内存和 AXI4-Stream 目标外设之间进行数据传输,例如高速转换器等。AXI DMAC驱动1.dmac设备树节点先从设备树开始看吧,下面是一个dw dmac节点的一个示例, dmac: dma-controller@5700000 { compatible = "snps,axi-dma-1.01a"; reg = <0x5700000 0x100000>; clocks = <&dmacoreclk>, <&dmacfgrclk>; clock-names = "core-clk", "cfgr-clk"; interrupts = <GIC_SPI 13 IRQ_TYPE_LEVEL_HIGH>; dma-channels = <8>; snps,dma-masters = <2>; snps,data-width = <4>; snps,block-size = <512 512 512 512 512 512 512 512>; snps,priority = <0 1 2 3 4 5 6 7>; snps,axi-max-burst-len = <256>; status = "okay"; };根据dw文档,各个节点属性的含义如下,Synopsys DesignWare AXI DMA Controller Required properties: - compatible: "snps,axi-dma-1.01a" - reg: Address range of the DMAC registers. This should include all of the per-channel registers. - interrupt: Should contain the DMAC interrupt number. - dma-channels: Number of channels supported by hardware. - snps,dma-masters: Number of AXI masters supported by the hardware. - snps,data-width: Maximum AXI data width supported by hardware. (0 - 8bits, 1 - 16bits, 2 - 32bits, ..., 6 - 512bits) - snps,priority: Priority of channel. Array size is equal to the number of dma-channels. Priority value must be programmed within [0:dma-channels-1] range. (0 - minimum priority) - snps,block-size: Maximum block size supported by the controller channel. Array size is equal to the number of dma-channels. Optional properties: - snps,axi-max-burst-len: Restrict master AXI burst length by value specified in this property. If this property is missing the maximum AXI burst length supported by DMAC is used. [1:256] Example: dmac: dma-controller@80000 { compatible = "snps,axi-dma-1.01a"; reg = <0x80000 0x400>; clocks = <&core_clk>, <&cfgr_clk>; clock-names = "core-clk", "cfgr-clk"; interrupt-parent = <&intc>; interrupts = <27>; dma-channels = <4>; snps,dma-masters = <2>; snps,data-width = <3>; snps,block-size = <4096 4096 4096 4096>; snps,priority = <0 1 2 3>; snps,axi-max-burst-len = <16>; };
DW AXI DMAC简单理解 DMAC简介DMAC(AXI Direct Memory Access Controller)是一种高速、高吞吐量的通用 DMA 控制器,用于在系统内存和其他外设之间传输数据。AXI 表示 Advanced eXtensible Interface,是一种高性能、低延迟的总线协议,用于连接不同的硬件模块,例如处理器、DMA 控制器、存储器、外设等AXI DMAC 是一种特定于 AXI 总线的 DMA 控制器,支持高带宽、直接内存访问。它可以在内存和 AXI4-Stream 目标外设之间进行数据传输,例如高速转换器等。AXI DMAC驱动1.dmac设备树节点先从设备树开始看吧,下面是一个dw dmac节点的一个示例, dmac: dma-controller@5700000 { compatible = "snps,axi-dma-1.01a"; reg = <0x5700000 0x100000>; clocks = <&dmacoreclk>, <&dmacfgrclk>; clock-names = "core-clk", "cfgr-clk"; interrupts = <GIC_SPI 13 IRQ_TYPE_LEVEL_HIGH>; dma-channels = <8>; snps,dma-masters = <2>; snps,data-width = <4>; snps,block-size = <512 512 512 512 512 512 512 512>; snps,priority = <0 1 2 3 4 5 6 7>; snps,axi-max-burst-len = <256>; status = "okay"; };根据dw文档,各个节点属性的含义如下,Synopsys DesignWare AXI DMA Controller Required properties: - compatible: "snps,axi-dma-1.01a" - reg: Address range of the DMAC registers. This should include all of the per-channel registers. - interrupt: Should contain the DMAC interrupt number. - dma-channels: Number of channels supported by hardware. - snps,dma-masters: Number of AXI masters supported by the hardware. - snps,data-width: Maximum AXI data width supported by hardware. (0 - 8bits, 1 - 16bits, 2 - 32bits, ..., 6 - 512bits) - snps,priority: Priority of channel. Array size is equal to the number of dma-channels. Priority value must be programmed within [0:dma-channels-1] range. (0 - minimum priority) - snps,block-size: Maximum block size supported by the controller channel. Array size is equal to the number of dma-channels. Optional properties: - snps,axi-max-burst-len: Restrict master AXI burst length by value specified in this property. If this property is missing the maximum AXI burst length supported by DMAC is used. [1:256] Example: dmac: dma-controller@80000 { compatible = "snps,axi-dma-1.01a"; reg = <0x80000 0x400>; clocks = <&core_clk>, <&cfgr_clk>; clock-names = "core-clk", "cfgr-clk"; interrupt-parent = <&intc>; interrupts = <27>; dma-channels = <4>; snps,dma-masters = <2>; snps,data-width = <3>; snps,block-size = <4096 4096 4096 4096>; snps,priority = <0 1 2 3>; snps,axi-max-burst-len = <16>; }; -
宋宝华:论Linux的页迁移(Page Migration)完整版 版权声明:本文为CSDN博主「宋宝华」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/21cnbao/article/details/108067917对于用户空间的应用程序,我们通常根本不关心page的物理存放位置,因为我们用的是虚拟地址。所以,只要虚拟地址不变,哪怕这个页在物理上从DDR的这里飞到DDR的那里,用户都基本不感知。那么,为什么要写一篇论述页迁移的文章呢?我认为有2种场景下,你会关注这个Page迁移的问题:一个是在Linux里面写实时程序,尤其是Linux的RT补丁打上后的情况,你希望你的应用有一个确定的时延,不希望跑着跑着你的Page正在换位置而导致的延迟;再一个场景就是在用户空间做DMA的场景,尤其是SVA(SharedVirtual Addressing),设备和CPU共享页表,设备共享进程的虚拟地址空间的场景,如果你DMA的page跑来跑去,势必导致设备DMA的暂停,设备的传输性能出现严重抖动。这种场景下,设备的IOMMU和CPU的MMU会共享Page table:1. COW导致的页面迁移1.1 fork典型的CoW(写时拷贝)与fork()相关,当父子兄弟进程共享一部分page,而这些page本身又应该是具备独占属性的时候,这样的page会被标注为只读的,并在某进程进行写动作的时候,产生page fault,其后内核为其申请新的page。比如下面的代码中,把10写成20的进程,在写的过程中,会得到一页新的内存,data原本的虚拟地址会指向新的物理地址,从而发生page的migration。类似的场景还有页面的私有映射引发的CoW:运行这个程序,通过smem观察,可以明显看到,父进程执行新的写后(程序打印“cow is done in parent process”后),父子进程不再共享相关page,他们的USS/PSS都显著增大:由fork衍生的写时拷贝场景相对来说比较基础,在此我们不再赘述。1.2 KSM其他的CoW的场景有KSM(Kernel same-page merging)。KSM会扫描多个进程的内存,如果发现有page的内容是一模一样的,则会将其merge为一个page,并将其标注为写保护的。之后对这个page执行CoW,谁写谁得到新的拷贝。比如,你在用qemu启动一个虚拟机的时候,使用mem-merge=on,就可以促使多个VM共享许多page,从而有利于实现“超卖”。sudo /x86_64-softmmu/qemu-system-x86_64 \ -enable-kvm -m 1G \ -machine mem-merge=on不过这本身也引起了虚拟机的一些安全漏洞,可被side-channel攻击。比如,把下面的代码编译为a.out,并且启动两份a.out进程./a.out&./a.out代码:我们看到这2个a.out的内存消耗情况如下:但是,如果我们把中间的if 0改为if 1,也就是暗示mmap()的这1MB内存可能要merge,则耗费内存的情况发生显著变化:耗费的内存大大减小了。我们可以看看pageshare的情况:Merge发生在进程内部,也发生在进程之间。当然,如果在page已经被merge的情况下,谁再写merge过的page,则会引起写时拷贝,比如如下代码中的p[0]=100这句话。2. 内存规整导致的页面迁移2.1 CMA引起的内存迁移CMA (The Contiguous Memory Allocator)可运行作为dma_alloc_coherent()的后端,它的好处在于,CMA区域的空闲部分,可以被应用程序拿来申请MOVABLE的page。如下图中的一个CMA区域的红色部分已经被设备驱动通过dma_alloc_coherent()拿走,但是蓝色部分目前被用户进程通过malloc()等形式拿走。一旦设备驱动继续通过dma_alloc_coherent()申请更多的内存,则内核必须从别的非CMA区域里面申请一些page,然后把蓝色的区域往新申请的page移走。用户进程占有的蓝色page发现了迁移。CMA在内核的配置选项中依赖于MMU,且会自动使能MIGRATION(Pagemigration)和MEMORY_ISOLATION:2.2 alloc_pages当内核使能了COMPACTION,则Linux的底层buddy分配器会在alloc_pages()中尝试进行内存迁移以得到连续的大内存。COMPACTION这个选项也会使能CMA一节提及的MIGRATION选项。从代码的顺序上来看,alloc_pages()分配order比较高的连续内存的时候,是优先考虑COMPACTION,再次考虑RECLAIM的。2.3 /proc/sys/vm/compact_memory当然,上面alloc_pages所提及的compaction也可以被用户手动的触发,触发方式:echo 1 >/proc/sys/vm/compact_memory将1写入compact_memory文件,则内核会对各个zone进行规整,以便能够尽可能地提供连续内存块。我的Ubuntu已经运行了一段时间,内存稍微有些碎片化了,我们来对比下手动执行compact_memory前后,buddy的情况:可以清晰地看出来,执行compact_memory后,DMA32 ZONE和NORMAL ZONE里面,order比较大的连续page数量都明显增大了。2.4 huge page再次展开内核的COMPACTION选型,你会发现COMPACTION会被透明巨页自动选中:这说明透明巨页是依赖于COMPACTION选项的。所谓透明巨页,无非就是应用程序在运行的时候,神不知鬼不觉地偷偷地就使用到了Hugepage的功能,这个过程对用户是透明的。与透明对应的无非就是不透明的巨页,这种方式下,应用程序需要显示地告诉内核我需要使用巨页。我们先来看看不透明的巨页是怎么玩的?一般用户程序可以这样写,在mmap里面会加上MAP_HUGETLB的Flag,当然这个巨页也必须是提前预设好的,否则mmap就会失败。ptr_ = mmap(NULL, memory_size_, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS | MAP_HUGETLB, -1, 0);比如下面的代码我们想申请2MB的巨页:程序执行的时候会返回错误,打印如下:$ ./a.out Hugetlb: Cannot allocate memory原因很简单,因为现在系统里面2MB的巨页数量和free的数量都是0:我们如何让它申请成功呢?我们首先需要保证系统里面有一定数量的巨页。这个时候我们可以写nr_hugepages得到巨页:我们现在让系统得到了10个大小为2048K的巨页。现在来重新运行a.out,就不在出错了,而且系统里面巨页的数量发生了变化:Free的数量从10页变成了9页。聪明的童鞋应该想到了,当我们尝试预留巨页的时候,它最终还是要走到buddy,假设系统里面没有连续的大内存,系统是否会进行内存迁移以帮忙规整出来巨页呢?这显然符合前面说的alloc_pages()的逻辑。从alloc_buddy_huge_page()函数的实现也可以看出这一点:另外,这种巨页的特点是“预留式”的,不会free给系统,也不会被swap。因此可有效防止用户态DMA的性能抖动。对于DPDK这样的场景,人们喜欢这种巨页分配,减少了页面的数量和TLB的miss,缩短了虚拟地址到物理地址的重定位的转换时间,因此提高了性能。当然,我们在运行时通过写nr_hugepages的方法设置巨页,这种方法未必一定能够成功。所以,工程中也可以考虑通过内核启动的bootargs来设置巨页,这样Linux开机的过程中,就可以直接从bootmem里面分配巨页,而不必在运行时通过order较高的alloc_pages()来获取。这个在内核文档的kernel-parameters.txt说的比较清楚,你可以在bootargs里面设置各种不同hugepagesize有多少个页数:透明巨页听起来是比较牛逼的,因为它不需要你在应用程序里面通过MAP_HUGETLB来显式地指定,但是实际的使用场景则未必这么牛逼。使用透明巨页的最激进的方法莫过于把enabled和defrag都设置为always:echo always >/sys/kernel/mm/transparent_hugepage/enabled echo always >/sys/kernel/mm/transparent_hugepage/defragenabled写入always暗示对所有的区域都尽可能使用透明巨页,defrag写入always暗示内核会激进地在用户申请内存的时候进行内存回收(RECLAIM)和规整(COMPACTION)来获得THP(透明巨页)。我们来前面的例子代码稍微进行更改,mmap16MB内存,并且去掉MAP_HUGETLB:运行这个程序,并且得到它的pmap情况:我们发现从00007f46b0744000开始,有16MB的anon内存区域,显然对应着我们代码里面的mmap(16*1024*1024)的区域。我们进一步最终/proc/15371/smaps,可以得到该区域的内存分布情况:显然该区域是THPeligible的,并且获得了透明巨页。内核文档filesystems/proc.rst对THPeligible的描述如下:"THPeligible" indicates whether the mapping is eligible for allocating THP pages - 1 if true, 0 otherwise. It just shows the current status.透明巨页的生成,显然会涉及到前面的内存COMPACTION过程。透明巨页在实际的用户场景里面,可能反而因为内存的RECLAIM和COMPACTION而降低了性能,比如有些VMA区域的寿命很短申请完使用后很快释放,或者某些使用大内存的进程是短命鬼,进行规整花了很久,而跑起来就释放了这部分内存,显然是不值得的。类似《权力的游戏》中的夜王,花了那么多季进行内存规整准备干夜王这个透明巨页,结果夜王上来就被秒杀了,你说我花了多时间追剧冤不冤?所以,透明巨页在实际的工程中,又引入了一个半透明的因子,就是内核可以只针对用户通过madvise()暗示了需要巨页的区间进行透明巨页分配,暗示的时候使用的参数是MADV_HUGEPAGE:所以,默认情况下,许多系统会把enabled和defrag都设置为madvise:echo madvise >/sys/kernel/mm/transparent_hugepage/enabled echo madvise >/sys/kernel/mm/transparent_hugepage/defrag或者干脆把透明巨页的功能关闭掉:echo never >/sys/kernel/mm/transparent_hugepage/enabled echo never >/sys/kernel/mm/transparent_hugepage/defrag如果我们只对madvise的区域采用透明巨页,则用户的代码可以这么写:既然我都已经这么写代码了,我还透明个什么鬼?所以,我宁可为了某种确定性,而去追求预留式的,非swap的巨页了。3. NUMA Balancing引起的页面迁移在一个典型的NUMA系统中,存在多个NODE,很可能每个NODE都有CPU和Memory,NODE和NODE之间通过某种总线再互联。下面中的NUMA系统有4个NODE,每个NODE有24个CPU和1个内存,NODE之间通过红线互联:在这样的系统中,通常CPU访问本地NODE节点的memory会比较快,而跨NODE访问memory则会慢很多(红色总线慢)。所以Linux的NUMA自动均衡机制,会尝试将内存迁移到正在访问它的CPU节点所在的NODE,如下图中绿色的memory经常被CPU24访问,但是它位于NODE0的memory:则Linux内核可能会将绿色内存迁移到CPU24所在的本地memory:这样CPU24访问它的时候就会快很多。显然NUMA_BALANCING也是依赖MIGRATION机制的:下面我们来写个多线程的程序,这个程序里面有28个线程(一个主线程,26个dummy线程执行死循环,以及一个写内存的线程):我们开那么多线程的目的,无非是为了让write_thread_start对应的线程,尽可能地不被分配到主线程所在的NUMA节点。这个程序的主线程最开始写了64MB申请的内存,30秒后,通过write_done=1来暗示write_thread_start()线程你可以开始写了,write_thread_start()则会把这64MB也写一遍,如果主线程和write_thread_start()线程不在一个NODE节点的话,内存迁移就有可能发生。这是我们刚开始2秒的时候获得的该进程的numastat,可以看出,这64MB内存几乎都在NODE3上面:但是30秒后,我们再次看它的NUMA状态,则发生了巨大的变化:64MB内存跑到NODE1上面去了。由此我们可以推断,write_thread_start()线程应该是在NODE1上面跑,从而引起了这个迁移的发生。当然,我们也可以通过numactl--cpunodebind=2类似的命令来规避这个问题,比如:# numactl --cpunodebind=2 ./a.outNUMA Balancing的原理是通过把进程的内存一部分一部分地周期性地进行unmap(比如每次256MB),在页表里面把扫描的部分的PTE设置为 “no access permission” ,以在其后访问它的时候,强制产生pagefault,进而探测page fault发生在本地NODE还是远端NODE,来获知CPU和memory是否较远的。这说明,哪怕没有真实的迁移发生,NUMA balancing也会导致进程的内存访问出现Page fault。4. Page migration究竟是怎么做的?内存规整和NUMA平衡等引发的Page migration的过程,一言以蔽之,就是把一个page从A位置移动到B位置。正所谓“当官的一动嘴,当差的跑断腿”。这个过程真地是一点都不简单。在一个真实的工程场景中,由于共享内存等原因,一个page可能被多个进程share,被映射到多个进程的VMA里面去,所以这个迁移过程,要伴随多个进程的虚实映射的更改(迁移前后虚拟地址都是不变的)以及相关address_space的radix tree从指向A到指向B的变更。此外,新page对应的一些flags,应该和旧page是一样的。如果时间停止,比如一旦我们开启了迁移page A到page B的过程,进程1,2,3,4都站那里不动了,内核其他人也站那里不动了,这个过程还相对来说比较简单。真实的情况是,在我们把A迁移到B的过程中,进程1,2,3,4应该有可能还会访问迁移中的page对应的虚拟地址。当迁移正在进行中,“树欲静而风不止”,用户进程和内核其他子系统不会因为你“想静静”就给你“静静”。迁移的步骤非常繁杂,我们抓主干放弃细节,主要以clean的page的迁移为分析目标,抛开dirty页面的writeback问题。整个迁移的过程中,除了进程1-4可以访问page里面的内容,内核内存管理子系统其他的代码,也可能访问page对应的元数据。应该避免内核的内存管理的其他子系统进来干扰。比如,我正在迁移pageA,结果你的内存管理子系统还在LRU里面扫描A,比如把pageA从inactiveLRU移到activeLRU。明天新皇帝就要打进京城了,老皇帝今天晚上还在修皇宫,这么无私奉献的皇帝也有?所以,迁移的过程中,我们先要用__isolate_lru_page()把page从LRU里面隔离出来,不要再在明天就要挂的皇帝上面费心思了。因为,你一边在修改老page的元数据,一边老page在灭亡中,这也太乱了吧?还有一种情况,A皇明天就要禅位给B皇,结果你今天晚上把A皇灭了,比如pageA被回收释放了,那么明天的皇帝交接仪式还如何进行?__isolate_lru_page()的核心代码如下,它阻止了Page A被释放,同时也避免LRU的扫描动作: if (likely(get_page_unless_zero(page))) { /* * Be careful not to clear PageLRU until after we're * sure the page is not being freed elsewhere -- the * page release code relies on it. */ ClearPageLRU(page); ret = 0; }它把page的_refcount进行了增加,这样这个pageA就不会在迁移给B的过程中,被内存回收子系统free掉。另外,ClearPageLRU()会清除掉page的PG_lru标记,使得PageLRU(page)为假,从而阻止了很多类似如下的LRU代码路径:static void __activate_page(struct page *page, struct lruvec *lruvec, void *arg) { if (PageLRU(page) && !PageActive(page) && !PageUnevictable(page)) { int lru = page_lru_base_type(page); int nr_pages = hpage_nr_pages(page); del_page_from_lru_list(page, lruvec, lru); SetPageActive(page); lru += LRU_ACTIVE; add_page_to_lru_list(page, lruvec, lru); … } }隔离的准备工作完成,我们开始进行迁移,然后就到了令人痛不欲生的内核函数:int migrate_pages(struct list_head *from, new_page_t get_new_page, free_page_t put_new_page, unsigned long private, enum migrate_mode mode, int reason);如果你看内核的https://www.kernel.org/doc/html/latest/vm/page_migration.html文档,相信看到这个地方,一共有20步,一定懵逼了:这个步骤太多,比较难以理顺,所以我们重点是抓核心矛盾:迁移必须是无缝的,不能因为你的迁移导致进程不能正常运行,迁移过程中,进程还是可能访问正在迁移的page!当页面A正在迁移到B的过程,原先的进程1-4访问对应的虚拟地址的时候,这个访问其实没有什么不合法。所以,我们必须保证它还是可以访问,当然这个访问可能是有延后的。大体可以分为3个阶段:在迁移的早期阶段,进程的页表项还是指向page A的,映射了page A的用户进程还是可以无障碍地访问到A;在迁移的中期阶段,他们访问不到A了,因为A被unmap了,但是这个时候它其实也访问不了B,因为B还没有map。有那么一段时间是一个皇位悬空的状态。但是进程1-4访问这个虚拟地址没有什么不合法啊!我们甚至都不需要让进程1-4感知到我们正在迁移。所以,在这个悬空的期间,进程1-4对虚拟地址进行访问的时候,我们应该能感知到这个访问的发生并让他们稍作等待,以便新皇登基后他们继续访问;在迁移的末期阶段,page B被map,新皇登基完成,先皇被抛弃,我们应该唤醒在“中期阶段”的进程1-4对该虚拟地址的访问,并让进程1-4能访问到page B。第2阶段,根据被迁移的page寻找进程,寻找VMA,以操作他们的PTE,用到了反向映射技术RMAP;而PTE修改后,用户进程继续访问相关page对应的虚拟地址,则会发生page fault,发生page fault后,进程阻塞等待,等待在发生page fault的page的lock上面,这一点从__migration_entry_wait()这个page fault处理函数的核心函数的注释和代码流程可以看出:put_and_wait_on_page_locked()会将进程放入等待队列,等待page的PG_locked标记被清楚,也就是等待第3阶段的完成,从而实现了无缝地交接。5. 如何规避页迁移5.1 mlock可以吗?mlock()的主要作用是是防止swap。我们可以用mlock()锁住匿名页或者有文件背景的页面。如果匿名页被mlock住了,对应的内存不会被写入swap分区;如果文件背景的页面被mlock住了,相关的pagecache不会被reclaim。有文件背景的页面的mlock稍微有点难理解,所以我们用如下代码演示了有文件背景的mmap区域被mlock:由于我们mlock了,所以这4096个字节必须常驻内存!但是mlock()并不能保证这4096个字节对应的物理页面不迁移,它最主要的作用是防止page被swap。这一点从mlock()的manpage上面看地非常清楚:mlock(),mlock2(), and mlockall() lock part or all of the calling process's virtualaddress space into RAM, preventing that memory from being paged to the swaparea.为了实际证明被mlock()的page还是可能被迁移,我们把前面演示NUMA Balance页迁移的程序稍微进行改动,把malloc的64MB内存进行mlock():再运行这个程序,效果如下:我们明显看出,Node0上面的64MB内存,随着write_thread_start()的执行,被迁移到了NODE1。在Linux中,执行mlock()操作的时候,相应的VMA会被设置VM_LOCKED标记。当然,用户mlock()的区域大小,并不一定正好等于mlock()对应区域的VMA大小,所以mlock()的过程中,会进行VMA的拆分或合并(原因是同一个VMA里面的flags应该是一样的)。我们都本着眼见为实的原则,用代码来说话。把前面那段文件背景页面的被mlock()前后进程的VMAdump一下,我们稍微改一下代码,mmap 1M但是只mlock其中的4K:在mlock前后我们dump这个进程的VMA。mlock前,我们看到一段1024K的VMA区域,背景为/home/baohua/file:在mlock()后我们再次观察,我们看到这个1024k被拆分了1020k+4k:开始的4K由于有了单独的VMA特性,1024被拆分为4+1020两个VMA。mlock()锁定区域的page,也会被mark成PG_mlocked(注意不是PG_locked),相关页面会被放入unevictable_list链表,page变成不可回收的page,从LRU剥离。与unevictable相反的page是可回收的,此类page会进入inactive或者activeLRU,内核的swap机制会扫描相关page和LRU决定对最不活跃的page进行回收。根据内核文档https://www.kernel.org/doc/Documentation/vm/unevictable-lru.txt,Linux supports migration of mlocked pages and otherunevictable pages. This involves simplymoving the PG_mlocked and PG_unevictable states from the old page to the newpage.所以,对于mlock()的page,还是可能被迁移,只是迁移后,在迁移完成的目标page上面,保留了原先的PG_mlocked标记,新的page还是LRU剥离的,仍然不会被swap机制扫描到。至于这种不可回收page的内存规整动作是否应该进行,则可以由/proc/sys/vm/compact_unevictable_allowed参数进行控制。如果我们使能了它,内存规整的代码也会扫描unevictableLRU,对不可回收page进行页面迁移。透明巨页是一个神奇的存在,假设我们透明巨页的大小是2MB,如果我们mlock()其中的1MB,则没有被mlock()的1MB是可以被回收的,当内核进行内存回收动作的时候,可以将2MB再次拆分为一个个的4KBpage,从而保证没有被mlock()的部分可以被回收。5.2 GUP可以吗?我们已经发现mlock()不具备防止迁移的功能。那么,如果我们要用用户空间的buffer做DMA,常规的途径是什么呢?Linux内核可以用GUP(get_user_pages的衍生变体),来pin住page,从而避免相关的page被迁移或被swap代码释放。这实际上给针对用户空间的buffer进行DMA提供了某种形式的安全保障。前面我们说过,mlock()可以避免page的swap,但是没法避免page的迁移和old page的释放,所以,如果我们把用户空间的一片被mlock()的区域交给外设去做DMA,比如DMA的方向是DMA_FROM_DEVICE,由于设备感知到的是page A(app通过参数传递的方式给驱动传递了用户空间buffer,传递的时候buffer还对应page A),但是实际在DMA发生前,可能内存已经被迁移到了B,Page A甚至都释放给buddy或者被别的程序申请走了,这个时候设备做DMA,还是往A里面写,那么极有可能导致莫名其妙的崩溃发生。所以,对于用户空间的buffer,直接进行DMA的场景,我们必须保证当我们在app里把buffer传递给driver的时候,假设这个时候buffer对应page A在我们做DMA的时刻,以及DMA进行中的时刻,pageA都必须是一直存在的。这个pageA不能被释放、重新分配给第三者。具体是如何做到的呢?我们可以看看V4L2驱动,如果用户空间传一个指针进来进行DMA,V4L2驱动的内核态是如何处理的,相关代码位于drivers/media/v4l2-core/videobuf-dma-sg.c:videobuf_dma_init_user_locked()根据用户空间buffer的开始地址和大小,计算出page的数量,然后调用pin_user_pages()把这些page在内核pin住。pin_user_pages()这个函数位于mm/gup.c,属于GUP家族函数的一部分。该函数的功能,顾名思义,就是把用户的page pin住。Pin住和mlock()是完全不同的概率,mlock()是针对VMA添加VMA_LOCKED属性,针对VMA映射的page添加PG_mlocked属性,要求page不可reclaim不被swap,但是从pageA到page B的迁移仍然可能发生,pageA仍然可能被释放,但是这个释放也无关紧要,因为我们已经有了B。所以本质上,mlock(p, size)是对虚拟地址p ~ p+size-1常驻内存的一种保障,或者说是对有VM_LOCKED属性的VMA区域有常驻内存的page的一种保障,至于常驻的是A还是B,其实都不违背mlock()的语义。mlock强调长期有人值班,不能掉链子,而不在乎你换不换班。Pin是完全不同的语义,pin强调的是贞节牌坊式的坚守。pin是把buffer对应的page本身让它无法释放,因为pin的过程,会导致这个page的引用计数增加GUP_PIN_COUNTING_BIAS(值为1024,我理解是一种代码的hack,以区分常规的get_user_pages和pin_user_pages,常规的get只是+1,而pin的主要目的是为了用user space的buffer做DMA操作):Pin page并没有改变page所在VMA区域的语义,这是和mlock()之间很大的区别,mlock()会导致VMA区域得到VM_LOCKED,但是我们并没有一个VM_PINNED这样的东西。从用户场景上来看,内核驱动Pin住了USERPTR对应的memory后,进一步,V4L2的代码videobuf_dma_map()会把这个buffer转换为sg进行map_sg操作,之后就可以DMA了。所以pin最主要的作用是保证DMA动作不至于访问内存的时候踏空。如果我们不再需要这些userbuffer来进行DMA,相关的page应该被unpin:Unpin显然会导致一次引用计数减去GUP_PIN_COUNTING_BIAS的动作,如果ref减去GUP_PIN_COUNTING_BIAS的结果成为0,证明我们是最后一个用户,应该调用__put_page()促使page被正确释放:这里还有一个特别值得关注的地方,如果我们进行的是DMA_FROM_DEVICE,也就是设备到内存的DMA,则相关的page可能被设备而不是CPU写dirty了,我们把unpin_user_pages_dirty_lock()的最后一个参数设置为了TRUE,这样unpin_user_pages_dirty_lock()会把相关Page的dirty标记置上,否则Linux内核甚至都不知道设备写过这个page。pin_user_pages()在内核态增加了page的refcount,从而让内存管理的其他子系统不会释放这个page(尽管它没有像mlock那样把page从LRU上面拿下来,但是swap的代码也不可能释放它),也成功地阻止了page migration在这一个page上面的发生,甚至我们想去hot remove被pin的page所在的内存,都不可能成功了。对于我们关注的页面迁移问题,pagemigration的代码会检查page的refcount,refcount不合适的page(pin本身导致了refcount不符合expected_count),不会被迁移:所以,被pin的userspace page总体是DMA安全的。这里还有2个比较tricky的问题:1.就是用户的page,被内核pin住了,用户在unpin之前进行unmap呢?首先我们不欢迎这样的动作,对于pin的主要场景如RDMA、VFIO等,我们强调pin住的page是LONGTERM的,一般用户空间弄好buffer,应该一直复用这个buffer。详见内核文档:core-api/pin_user_pages.rst也可以看include/linux/mm.h的一段注释:实际上,用户空间应该控制这个buffer是indefinite的。如果万一pin住的页面用户层面真地在unpin之前就unmap了呢?pin的refcount其实也阻止了这个page被释放,只是这个page所在对应的虚拟地址由于被unmap了,所以不再对CPU可见了。当然,还有一个madvise(p, size, MADV_DONTNEED),其行为更加诡异,曾经臭名昭著的DirtyCoW漏洞(CVE-2016-5195),就与它息息相关。它并不是unmap,但是暗示内核它对某段地址访问暂时完成了使命很长一段时间不想访问了,并且去掉了页表的映射。这样后期再次访问这个地址p~ p+size-1的时候,如果p底层对应的是一个共享映射,可以获得老page的值;如果底层对应的是一个MAP_PRIVATE的映射,则按需获得一个0填充的页面:MADV_DONTNEED显然也是与pin的语义是违背的,这属于不“under userspace control”的情况了。如果我们真地对私有映射的pin区域执行了MADV_DONTNEED呢?显然pin也阻止了相关page被释放,但是当CPU重新访问page对应的虚拟地址的时候,MADV_DONTNEED却要求“the caller will see zero-fill-on-demand pages upon subsequent page references”,所以你不能指望先用MADV_DONTNEED暗示了自己不要这个memory了,然后再反过来期待DMA后CPU还能获取到自己曾经抛弃的内存,因为“是你当初说分手,分手就分手,现在又要用真爱把我哄回来,爱情不是你想卖,想买就能卖,让我挣开,让我明白,放手你的爱”。下面的代码映射100MB,但是只对其中的前2页执行MADV_DONTNEED:程序运行打印的结果如下:前2页变成了0,第3页还是100。2.如果pin住的区域是一个私有映射的区域(mmap的时候,使用了MAP_PRIVATE),然后在此区域执行了CoW会怎样?在下面的代码中,我们有个假想的设备驱动/dev/kernel-driver-with-pin-support,它支持一个IOCTL来让用户pin userspace的page。此例中,pin的这部分内存是私有映射的,而父进程又fork了子进程,之后父进程尝试写自己pin过的区域,这时会引发写时拷贝(CoW),从而让p对应的底层page发生变化:这种编程方式,实际上也违背了用户空间应该控制这个buffer是indefinite的原则,只是更加隐晦,所以要用userspace buffer做DMA的话,也应该尽可能避免这种编程方式,一般要对用户态buffer做DMA的进程,应该是叶子进程。如果一定要fork,可以考虑对pin住的区域执行madvise(p, size, MADV_DONTFORK),以避免CoW,具体的原理在madvise的man page上说地很清楚:5.3 使用巨页?我们如果用户空间是用非透明的巨页的话,实际上这种巨页是“预留式”的,因此可有效的避免内存的回收、swap和因为memory compaction、Automatic NUMA balancing等导致的page migration等。一般用户这么获得hugetlb内存:base_ptr_ = mmap(NULL, memory_size_, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS | MAP_HUGETLB, -1, 0);它实际上免去了对pin、mlock()等的需求。由于巨页本身可减小TLB miss以及walk page table的路径长度,想必可带来性能提升。一般情况下,当我们想在系统预留n个巨页的时候,若系统有m个NUMA节点,Linux会倾向于每个NUMA节点预留n/m个巨页。如果采用内存本地化的NUMA策略,任务运行在节点A的话,内核会倾向于从节点A预留的巨页向目标任务分配,所以我们最好是对任务进行一下NUMA的绑定。6. 最后的话在对用户空间代码进行轻微控制的情况下,GUP是比较理想的、抗性能抖动的、安全的针对用户空间buffer进行DMA的途径。当然,某些场景下,用户空间程序具有很大的灵活多变性,比如经常要动态malloc、free,我们又要在这样的heap上面去做DMA,每次都去pin和unpin显然是不现实的。这个时候我们可以借用Linux实时编程技术里面常常采用的,让malloc/free在一个存在的堆池发生分配和释放的技术:诀窍就在于先申请一个大堆,通过mallopt(M_TRIM_THRESHOLD, -1UL)避免大堆在free的时候还给内核。之后所有的malloc,free,都是在事先预留好的大堆进行,不再需要每次malloc/free区域单独pin,它带来了类似SVA的编程灵活性。如果用户空间采用无GUP的SVA方案,我们可能需考虑屏蔽如下功能以防止性能抖动:避免使用transparent huge pages (THP);避免使用kernel samepage merging (KSM);避免使用automatic NUMA balancing;避免运行时修改非透明巨页的数量;避免因为CMA而触发的页迁移;对需要做DMA的区域执行mlock()避免其被swap。当然上述问题几乎都可以被用户应用使用非透明巨页来规避,因为非透明巨页天然获得“预留式”内存的特征。当然这种方法绑死了用户应用必须使用hugetlbfs的逻辑,可能要求用户修改bootargs等来在系统启动过程中预留巨页。
-
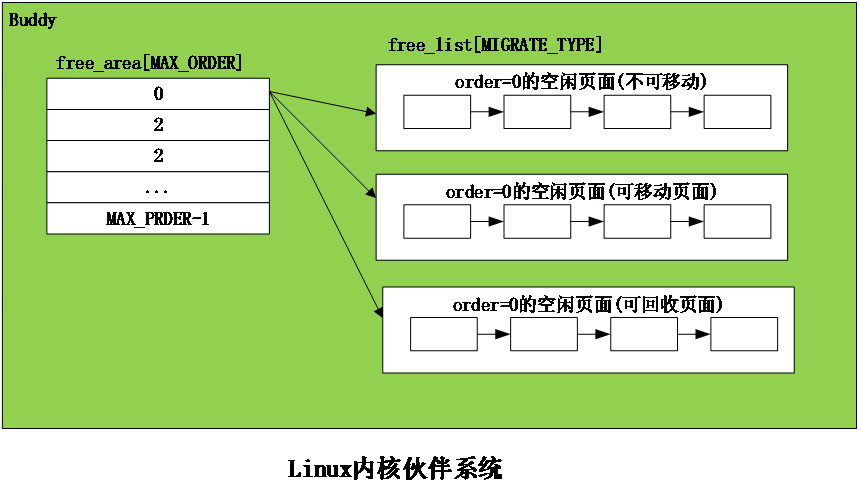
Linux内存管理--CMA技术原理分析 转载自https://blog.csdn.net/feelabclihu/article/details/129457653?spm=1001.2014.3001.5502前言本文介绍CMA(Contiguous Memory Allocator)技术原理,从源码分析CMA的初始化和分配流程,同时讲解涉及到的页面迁移、LRU(Least Rencntly Used)缓存、PCP(per cpu page)缓存等知识。1. CMA概述CMA是什么?为什么需要CMA?Linux伙伴系统(Buddy)使用 Page 粒度来管理内存,每个页面大小为4K。伙伴系统按照空闲内存块的长度,把内存挂载到不同长度的 free_list链表中。free_list 的单位是以 (2^order个Page) 来递增的,即 1 page、2 page、… 2^n,通常情况下最大 order 为10 对应的空闲内存大小为 4M bytes。我们使用伙伴系统来申请连续的物理页面最大的页面最大小4M bytes,且系统内存碎片化严重的时候,也很难分配到高order的页面。嵌入式系统上一些外设设备,如GPU、Camera,HDMI等都需要预留大量连续内存才能正常工作,且很多情况下仅4M连续内存是不足以满足设备的需求的,当然我们也可以使用memblock预留内存的方法来保留更大的连续内存,但这部分内存只能被设备所使用而Buddy使用不到,会导致内存浪费。CMA由此而生,我们即要能分配连续的大的内存空间给设备使用,平时设备不用时又要把内存给系统用,最大化利用内存。CMA连续内存分配器,主要是为了可用于分配连续的大块内存。系统初始化的时候会通过保留一片物理内存区域,平时设备驱动不用时,内存管理系统将该区域用于分配和管理可移动类型页面,提供给APP或者内核movable页面使用。设备驱动使用时,此时已经分配的页面则进行迁移走,该区域用于连续内存分配。在后续的章节中,我们主要通过阅读源码的方式,来介绍CMA的初始化、分配和页面迁移流程等。注:后续文中所贴源码为kernel5.4版本,代码截图会省略次要代码,只保留关键代码。2. CMA主要数据结构和API2.1 struct cma使用struct cma来描述一个CMA区域:base_pfn:CMA区域物理地址的起始page frame number(页帧号)count: CMA区域的页面数量bitmap:描述cma区域页面的分配情况,1表示已分配,0为空闲。order_per_bit:表示bitmap中一个bit所代表的页面数量(2^order_per_bit)。2.2 cma_init_reserved_mem从保留内存块里面获取一块地址为base、大小为size的内存,用来创建和初始化struct cma。2.3 cma_init_reserved_areascma_init_reserved_areas()-->cma_activate_area()-->init_cma_reserved_pageblock()-->set_pageblock_migratetype(page, MIGRATE_CMA)为了提升内存利用率,该函数用来将这CMA内存标记后归还给 buddy 系统,供 buddy作为可移动页面内存申请。2.4 cma_alloc用来从指定的CMA 区域上分配count个连续的页面,按照align对齐。2.5 cma_release用来释放已经分配count个连续的页面。3. CMA主要流程分析3.1 CMA初始化流程3.1.1 系统初始化:系统初始化过程需要先创建CMA区域,创建方法有:dts的reserved memory或者通过命令行参数。这里我们看经常使用的通过dts的reserved memory方式,物理内存的描述放置在dts中配置,比如:linux,cma 为CMA 区域名称。compatible须为“shared-dma-pool”。resuable 表示 cma 内存可被 buddy 系统使用。size 表示cma区域的大小,单位为字节alignment指定 CMA 区域的地址对齐大小。linux,cma-default 属性表示当前 cma 内存将会作为默认的cma pool 用于cma 内存的申请。在系统启动过程中,内核对上面描述的dtb文件进行解析,从而完成内存信息注册,调用流程为:setup_arch arm64_memblock_init early_init_fdt_scan_reserved_mem __reserved_mem_init_node__reserved_mem_init_node会遍历__reservedmem_of_table section中的内容,检查到dts中有compatible匹配(CMA这里为“shared-dma-pool”)就进一步执行对应的initfn。通过RESERVEDMEM_OF_DECLARE定义的都会被链接到__reservedmem_of_table这个section段中,最终会调到使用RESERVEDMEM_OF_DECLARE定义的函数,如下rmem_cma_setup:3.1.2 rmem_cma_setupcma_init_reserved_mem 从保留内存块里面获取一块地址为base、大小为size的内存,这里用dtb中解析出来的地址信息来初始化CMA,用来创建和初始化struct cma,代码很简单:如果dts指定了linux,cma-default,则将dma_contiguous_set_default指向这个CMA区域,使用dma_alloc_contiguous从CMA分配内存时,默认会从该区域分。执行到此, CMA和其它的保留内存是一样的,都是放在 memblock.reserved 中,这部分保留内存一样没能被 Buddy 系统用到。前面讲过为了提升内存利用率,还需要将CMA这部分内存标记后归还给 Buddy系统,供 Buddy作为可移动页面提供给APP或内核内存申请,由cma_init_reserved_areas来实现。3.1.3 cma_init_reserved_areas在内核初始化的后期会调用core_initcall描述的初始化函数:cma_init_reserved_areas,它直接调用cma_activate_area来实现。cma_activate_area根据cma大小分配bitmap,然后循环调用init_cma_reserved_pageblock来操作CMA区域中所有的页面, 看下源码:@1 CMA区域由一个bitmap来管理各个page的状态,cma_bitmap_maxno计算Bitmap需要多少内存,i变量表示该CMA eara有多少个pageblock(4M)。@2 遍历该CM区域中的所有的pageblock@3 确保CMA区域中的所有page都是在一个zone内@4 最终调用init_cma_reserved_pageblock,以pageblock为单位进行处理,设置migrate type为MIGRATE_CMA,将页面添加到伙伴系统中并更新zone管理的页面总数。如下:@1 将页面已经设置的reserved标志位清除掉。@2 将migratetype设置为MIGRATE_CMA@3 循环调用__free_pages函数,将CMA区域中所有的页面都释放到buddy系统中。@4 更新伙伴系统管理的内存数量。执行到此,后续这部分CMA内存就可以为buddy所申请。在伙伴系统中migratetype为movable并且分配flag带CMA,可以从CMA分配内存:3.2 CMA分配流程在阅读cma分配流程代码前,我们先看下它的函数调用流程,后面将通过源码对流程及各个函数进行分析。3.2.1 cma_alloc@1 bitmap的计算,主要是获取bimap最大的可用bit数(bitmap_maxno),此次分配需要多大的bitmap(bitmap_count)等。@2 根据上面计算得到的bitmap信息,从bitmap中找到一块空闲的位置。@3 一些特别情况(在后面会讲到)经常会导致CMA分配失败,当分配返回EBUSY时,需要msleep(100)再retry,默认会retry 5次。@4 将要分配的页面的对应bitmap先置位为1,表示已经分配了。@5 使用alloc_config_range来进行内存分配,在后面节详细分析。@6 分配失败则清除掉bitmap。3.2.2 内核中的“批处理”:LRU缓存和PCP缓存在分析alloc_config_range之前,先插讲两个知识点LRU缓存和PCP缓存,在阅读内核源码中,我们会发现内核很喜欢使用一些“批处理”的方法来提升效率,减少一些拿锁开销。1.LRU 缓存经典的LRU(Least Rencntly Used)链表算法如下图:注:详细的LRU算法介绍可以参考内核工匠之前的文章:kswapd介绍新分配的页面不断地加入ACTIVE LRU链表中,同时ACTIVE LRU链表也不断地取出将页面放入 INACTIVE LRU链表。链表中的锁(pgdat->lru_lock)竞争力度是非常强烈的,如果页面转移是一个一个进行的,那对锁的竞争将会十分严重。为了改善这种情况,内核加入了一个 PER-CPU的 LRU缓存(用 struct pagevec 表示),页面要加入LRU链表会先放入当前 CPU 的LRU缓存 中,直到LRU缓已经满了(一般为15个页面),再获取lru_lock,一次性将这些页面批量放入LRU链表。2.PCP(PER-CPU PAGES)缓存由于内存页面属于公共资源,系统中频繁分配释放页面,会因为获得释放锁(zone->lock),CPU之间的同步操作产生大量消耗。同样为了改善这种情况,内核加入了per cpu page 缓存(struct per_cpu_pages表示),每个CPU都从Buddy批发申请少量的页面存放在本地。当系统需要申请内存时,优先从PCP缓存拿,用完了再从buddy批发。释放时也优先放回该PCP缓存,缓存满了再放回buddy系统。内核之前只支持order=0的PCP,社区最新已经有补丁可以支持order>0的per-cpu。3.2.3 alloc_config_range函数:继续看cma_alloc流程的alloc_config_range要干哪些事情:简而言之,目的就是想从一块“脏的”连续内存块(已经被各种类型的内存使用),得到一块干净的连续内存块,要么是回收掉,要么是迁移走,最后将这块干净的连续内存返回给调用者使用,如下图:走读下代码:@1 start_isolate_page_range:将目标内存块的pageblock 的迁移类型由MIGRATE_CMA 变更为 MIGRATE_ISOLATE。因为buddy系统不会从 MIGRATE_ISOLATE 迁移类型的pageblock 分配页面,可以防止在cma分配过程中,这些页面又被人从Buddy分走。@2 drain_all_pages:回收per-cpu pages,前面已经有介绍过PCP,回收过程需要先将放在PCP缓存页面归还给Buddy。@3 __alloc_contig_migrate_range:将目标内存块已使用的页面进行迁移处理,迁移过程就是将页面内容复制到其他内存区域,并更新对该页面的引用。@3.1 lru_cache_disable: 因为在LRU缓存的页面是无法迁移的,需要先将pagevec页面刷到LRU,即将准备添加到LRU链表上,却还未加入LRU的页面(还待在LRU缓存)添加到LRU上,并关闭LRU缓存功能。@3.2 isolate_migratepages_range 隔离要分配区域已经被Buddy使用的page,存放到cc的链表中,返回的是最后扫描并处理的页框号。这里隔离主要是防止后续迁移过程,page被释放或者被LRU回收路径使用。@3.3 reclaim_clean_pages_from_list:对于干净的文件页,直接回收即可。@3.4 migrate_pages:该函数是页面迁移在内核态的主要接口,内核中涉及到页面迁移的功能大都会调到,它把可移动的物理页迁移到一个新分配的页面。在下一节详细介绍它。@3.5 lru_cache_enable迁移过程完成,重新使能LRU PAGEVEC@4.undo_isolate_page_range: @1的逆过程pageblock的迁移类型从 MIGRATE_ISOLATE 恢复为 MIGRATE_CMA。最后将这些页面返回给调用者。3.3 CMA释放流程cma_release释放CMA内存的代码很简单,就是把页面重新free给Buddy和清楚到cma的bitmap分配标识,这里直接贴一下代码:4. 页面迁移系统要使用CMA区域的内存,内存上的页面必须是可迁移的,这样子当设备要使用CMA时页面才能迁移走,那么哪些页面可以迁移呢?有两种类型:LRU上的页面,LRU链表上的页面为用户进程地址空间映射的页面,如匿名页和文件页,都是从buddy分配器migrate type为movable的pageblock上分来的。非LRU上,但是是movable页面。非LRU的页面通常是为kernel space分配的page,要实现迁移需要驱动实现page->mapping->a_ops中的相关方法。比如我们常见的zsmalloc内存分配器的页面就支持迁移。migrate_pages()是页面迁移在内核态的主要接口,内核中涉及到页面迁移的功能大都会调到它。如下图,migrate_pages()无非是要分配一个新的页面,断开旧页面的映射关系,重新简历映射到新的页面,并且要拷贝旧页面的内容到新页面、新页面的struct page属性要和旧页面设置得一样,最后释放旧的页面。下面来阅读下它的源码。4.1 migrate_pages:migrate_pages函数和参数:from: 准备迁移页面的链表get_new_page:申请新页面函数的指针putnew_page:释放新页面函数的指针private:传给get_new_page的参数,CMA这里没有使用到传NULLmode:迁移模式,CMA的迁移模式会设置为MIGRATE_SYNC。共有下面几种:reason:迁移原因,记录是什么功能触发了迁移的行为。因为内核许多路径都需要用migrate_pages来迁移比如还有内存规整、热插拔等。CMA传递的为MR_CONTIG_RANG,表示调用alloc_contig_range()分配连续内存。再看migrate_pages代码,它遍历 from链表,对每个page调用unmap_and_move来实现迁移处理。4.2 unmap_and_moveunmap_and_move函数的参数同migrate_pages一模一样,它调用get_new_page分配一个新页面,然后使用__unmap_and_move迁移页面到这个新分配的页面中,我们主要看下__unmap_and_move4.3 __unmap_and_move:@1尝试获取old page的页面锁PG_locked,若页面已经被其它进程持有了锁,则这里会尝试获取锁失败,对于MIGRATE_ASYNC模式的为异步迁移拿不到锁就直接跳过此页面。CMA迁移模式为MIGRATE_SYNC,这里一定使用lock_page一定要等到锁。@2处理正在回写的页面,根据迁移模式判断是否等待页面回写完成。MIGRATE_SYNC_LIGHT和MIGRATE_ASYNC不等待,cma迁移模式为MIGRATE_SYNC,会调用wait_on_page_writeback()函数等待页面回写完成。@3 对于匿名页,为了防止迁移过程anon_vma数据结构被释放了,需要使用page_get_anon_vma增加anon_vma->refcount引用计数。@4 获取new page的页面锁PG_locked,正常情况都能获取到。@5 判断这个页面是否属于非LRU页面,如果页面为非LRU页面,则通过调用move_to_new_page来处理,该函数会回调驱动的miratepage函数来进行页面迁移。如果是LRU页面,继续执行@6 @6 通过page_mapped()判断是否有用户PTE映射了改页面。如果有则调用try_to_unmap(),通过反向映射机制解除old page所有相关的PTE。@7 调用move_to_new_page,拷贝old page的内容和struct page属性数据到new page。对于LRU页面 move_to_new_page是通过调用migrate_page做了两件事:复制struct page的属性和页面内容。@8对页表进行迁移:remove_migration_ptes通过反向映射机制建立new page到进程的映射关系。@9 迁移完成释放old、new页面的PG_locked,当然对于匿名页我们也要put_anon_vma减少的anon_vma->refcount引用计数@10 对于非LRU页面,调用put_page,释放old page引用计数(_refcount减1)对于传统LRU putback_lru_page把newpage添加到LRU链表中。4.4 move_to_new_page在@5和@7中,非LRU和LRU页面都是通过move_to_new_page来复制页面,我们来看下他的实现:1.对于非LRU页面,该函数会回调驱动的miratepage函数来进行页面迁移比如在zsmalloc内存分配器会注册迁移回调函数,迁移流程这里会调用到zsmalloc的zs_page_migrate来迁移其申请的页面。zsmalloc内存分配器这里就不展开讲了,有兴趣的读者可以阅读zsmalloc的源码。2.对于LRU页面,调用migrate_page做了两件事:复制struct page的属性和页面内容。@7.1 struct page属性的复制:migrate_page_move_mapping 要先检查page的refcount是否符合预期,符合后之后会复制页面的映射数据,比如page->index、page->mapping以及PG_swapbacked这里顺带提一下refcount:refcount是struct page中重的引用计数,用来表示内核中引用改页面的次数。当refcount=0,表示该页面为空闲页面或即将要被释放的页面。当refcount的值>0,表示该页面已经被分配了且内核正在使用,暂时不会被释放。内核中使用get_page、pin_user_pages、get_user_pages等函数来增加_refcount的引用计数,可以防止在进行某些操作过程(比如添加入LRU)页面被其它路径释放了,同时他也会导致refcount不符合预期,也就是在这里不能迁移。@7.2 page页面内容的复制:copy_highpage就很简单了,使用kmap映射两个页面,再将旧页面的内存复制到新的页面。@7.3 migrate_page_states用来复制页面的flag,如PG_dirty,PG_XXX等标志位,也是属于struct page属性的复制。4.5 小结:整个迁移过程已经分析完,画出流程图如下,五、总结从上面章节分析,我们可以看到CMA的设计都是围绕这两点来做的:平时设备驱动不用时,CMA内存交给Buddy管理,这是在初始化流程cma_init_reserved_areas()或cma_release()来实现的。2.设备驱动要使用时,通过cma_alloc来申请物理连续的CMA内存。对于已经在Buddy被APP或者内核movable分配走了的页面,要通过回收或迁移将这块内存清理“干净”,最后将这块物理连续“干净”的内存返回给设备驱动使用。核心实现在alloc_config_range()和migrate_pages()函数。
-
从memblock中释放已经reserved的内存 1. 目的在有些应用场景中,有些reserved memory只在开机时使用,如开机logo之类的,在使用完成后可以选择释放这些reserved_memory,增大系统可用内存。如下面这样的reserved_memory,系统是无法使用的。2. 方法从memblock中的reserved memory中释放内存--memblock_free()将内存释放会buddy system管理-- free_reserved_page()3. 测试针对上面的logo_reserved,一个简单的测试驱动如下#include <linux/init.h> #include <linux/module.h> #include <linux/kernel.h> #include <linux/memblock.h> static int __init logo_init(void) { unsigned long mem_addr = 0xe6c00000; unsigned long size = 0x1000000; unsigned long pfn_start, pfn_end, pfn_idx; pfn_start = mem_addr >> PAGE_SHIFT; pfn_end = (mem_addr + size) >> PAGE_SHIFT; memblock_free(mem_addr, size); for (pfn_idx = pfn_start; pfn_idx < pfn_end; pfn_idx++) free_reserved_page(pfn_to_page(pfn_idx)); printk("logo_init!\n"); return 0; } static void __exit logo_exit(void) { } module_init(logo_init); module_exit(logo_exit); MODULE_LICENSE("GPL"); MODULE_AUTHOR("adtxl");测试结果如下,可以看到在加载驱动后,可用内存增大了16M,也就是logo_reserved这段内存的大小。
-
-
-
-
-
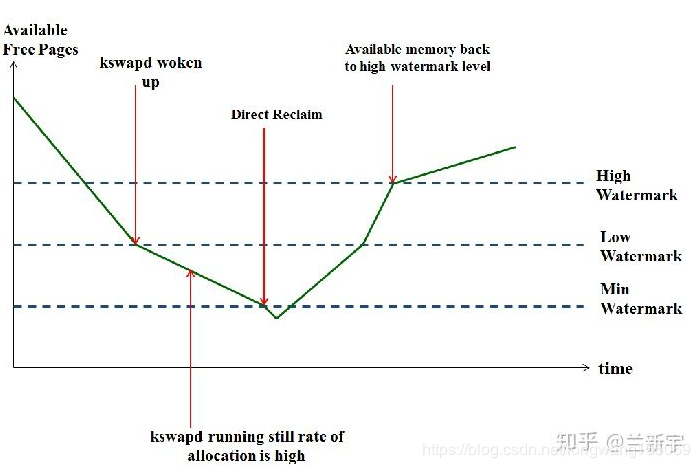
关于watermark的计算 关于watermark的概念请参考zoned page frame allocator--3(对watermark的理解)本文主要根据一个实例来加深理解1. zoneinfo的信息通过/proc/zoneinfo节点可以查看zone的相关信息,下面只截取了一部分,该开发平台只有1个node,也只有一直zone类型,即zone DMA32;Node 0, zone DMA32 ...... pages free 56388 min 1139 low 7295 high 7621 spanned 521952 present 345696 managed 326626 protection: (0, 0, 0) nr_free_pages 56388 ...... 这里的min、low、high的值是怎么计算出来的的呢?主要是依据min_free_kbytes的值,下面先分析下这个值是怎么计算出来的。2. min_free_kbytes值的计算根据文档Documentation/sysctl/vm.txt,============================================================== min_free_kbytes: This is used to force the Linux VM to keep a minimum number of kilobytes free. The VM uses this number to compute a watermark[WMARK_MIN] value for each lowmem zone in the system. Each lowmem zone gets a number of reserved free pages based proportionally on its size. Some minimal amount of memory is needed to satisfy PF_MEMALLOC allocations; if you set this to lower than 1024KB, your system will become subtly broken, and prone to deadlock under high loads. Setting this too high will OOM your machine instantly. =============================================================从上面的话得出了以下几点:min_free_kbyes代表的是系统保留空闲内存的最低限watermark[WMARK_MIN]的值是通过min_free_kbytes计算出来的系统中min_free_kbytes的值可以通过下面的节点查看。可以看到,这个4556/4=1139,就是上面min的值(因为我们这里只有一个zone DMA32)。console:/ # cat /proc/sys/vm/min_free_kbytes 4556下面的函数对每个zone做计算,将每个zone中超过high水位的值放到sum中。超过高水位的页数计算方法是:managed_pages减去watermark[WMARK_HIGH], 这样就可以获取到系统中各个zone超过高水位页的总和其中,high_wmark_pages(zone)获取的是watermark[WMARK_HIGH]的值,这里有个让我疑惑的地方是watermark[WMARK_HIGH]的值是根据watermark[WMARK_MIN]确定的,我们这里是为了计算watermark[WMARK_MIN],怎么会需要watermark[WMARK_HIGH]呢,在这里加个打印,发现在我的平台一开始获取的high值就是0,所以这里返回的就是managed_pages值,即326626/** * nr_free_zone_pages - count number of pages beyond high watermark * @offset: The zone index of the highest zone * * nr_free_zone_pages() counts the number of counts pages which are beyond the * high watermark within all zones at or below a given zone index. For each * zone, the number of pages is calculated as: * * nr_free_zone_pages = managed_pages - high_pages */ static unsigned long nr_free_zone_pages(int offset) { struct zoneref *z; struct zone *zone; /* Just pick one node, since fallback list is circular */ unsigned long sum = 0; struct zonelist *zonelist = node_zonelist(numa_node_id(), GFP_KERNEL); for_each_zone_zonelist(zone, z, zonelist, offset) { unsigned long size = zone->managed_pages; unsigned long high = high_wmark_pages(zone); if (size > high) sum += size - high; } return sum; } /** * nr_free_buffer_pages - count number of pages beyond high watermark * * nr_free_buffer_pages() counts the number of pages which are beyond the high * watermark within ZONE_DMA and ZONE_NORMAL. */ unsigned long nr_free_buffer_pages(void) { return nr_free_zone_pages(gfp_zone(GFP_USER)); } watermark的初始化是由下面的函数来完成的,将上面获取的值,即326626代入,可以算得在我们得平台上,min_free_kbytes得值为4572.与上面得4556大小基本相等。/* * Initialise min_free_kbytes. * * For small machines we want it small (128k min). For large machines * we want it large (64MB max). But it is not linear, because network * bandwidth does not increase linearly with machine size. We use * * min_free_kbytes = 4 * sqrt(lowmem_kbytes), for better accuracy: * min_free_kbytes = sqrt(lowmem_kbytes * 16) * * which yields * * 16MB: 512k * 32MB: 724k * 64MB: 1024k * 128MB: 1448k * 256MB: 2048k * 512MB: 2896k * 1024MB: 4096k * 2048MB: 5792k * 4096MB: 8192k * 8192MB: 11584k * 16384MB: 16384k */ int __meminit init_per_zone_wmark_min(void) { unsigned long lowmem_kbytes; int new_min_free_kbytes; lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10); new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16); if (new_min_free_kbytes > user_min_free_kbytes) { min_free_kbytes = new_min_free_kbytes; if (min_free_kbytes < 128) min_free_kbytes = 128; if (min_free_kbytes > 65536) min_free_kbytes = 65536; } else { pr_warn("min_free_kbytes is not updated to %d because user defined value %d is preferred\n", new_min_free_kbytes, user_min_free_kbytes); } // 建立各个zone得水位值 setup_per_zone_wmarks(); refresh_zone_stat_thresholds(); setup_per_zone_lowmem_reserve(); #ifdef CONFIG_NUMA setup_min_unmapped_ratio(); setup_min_slab_ratio(); #endif khugepaged_min_free_kbytes_update(); return 0; }3. 建立各个zone得水位值具体每个zone得水位值是由下面得函数确认的,static void __setup_per_zone_wmarks(void) { // pages_min = 4556/4=1139 unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10); // extra_free_kbytes机制应该是Android得patch,看了下5.18得kernel,还不包含这个patch,本平台这个值大小为24300 // page_low=24300/4=6075 unsigned long pages_low = extra_free_kbytes >> (PAGE_SHIFT - 10); unsigned long lowmem_pages = 0; struct zone *zone; unsigned long flags; // 计算除了ZONE_HIGHMEM之外所有的managed_pages之和,即lowmem_pages=326626 /* Calculate total number of !ZONE_HIGHMEM pages */ for_each_zone(zone) { if (!is_highmem(zone)) lowmem_pages += zone->managed_pages; } for_each_zone(zone) { u64 min, low; spin_lock_irqsave(&zone->lock, flags); // min = 1139*326626=372027014 min = (u64)pages_min * zone->managed_pages; // 取商,min = 1139, do_div(min, lowmem_pages); low = (u64)pages_low * zone->managed_pages; // vm_total_pages的值就是nr_free_pagecache_pages()的返回值,打log发现这个值是340294 // 也不是managed_pages值 // 所以下面计算后low的值在我们的平台还是pages_low=6075*326626/340294=5830 do_div(low, vm_total_pages); if (is_highmem(zone)) { /* * __GFP_HIGH and PF_MEMALLOC allocations usually don't * need highmem pages, so cap pages_min to a small * value here. * * The WMARK_HIGH-WMARK_LOW and (WMARK_LOW-WMARK_MIN) * deltas control asynch page reclaim, and so should * not be capped for highmem. */ unsigned long min_pages; min_pages = zone->managed_pages / 1024; min_pages = clamp(min_pages, SWAP_CLUSTER_MAX, 128UL); zone->watermark[WMARK_MIN] = min_pages; } else { /* * If it's a lowmem zone, reserve a number of pages * proportionate to the zone's size. */ // 在我们的平台,即走到这里,即求得了zone->watermark[WMARK_MIN]=1139 zone->watermark[WMARK_MIN] = min; } /* * Set the kswapd watermarks distance according to the * scale factor in proportion to available memory, but * ensure a minimum size on small systems. */ min = max_t(284,326),即min=326. min = max_t(u64, min >> 2, mult_frac(zone->managed_pages, watermark_scale_factor, 10000)); // Android打的patch,low的值在这里起了作用 // zone->watermark[WMARK_LOW]=1139+5830+326=7286 zone->watermark[WMARK_LOW] = min_wmark_pages(zone) + low + min; // watermark[WMARK_HIGH]即比zone->watermark[WMARK_LOW]多了个min的值 zone->watermark[WMARK_HIGH] = min_wmark_pages(zone) + low + min * 2; spin_unlock_irqrestore(&zone->lock, flags); } /* update totalreserve_pages */ calculate_totalreserve_pages(); } /** * setup_per_zone_wmarks - called when min_free_kbytes changes * or when memory is hot-{added|removed} * * Ensures that the watermark[min,low,high] values for each zone are set * correctly with respect to min_free_kbytes. */ void setup_per_zone_wmarks(void) { static DEFINE_SPINLOCK(lock); spin_lock(&lock); __setup_per_zone_wmarks(); spin_unlock(&lock); } 本平台得extra_free_kbytes值为24300console:/ # cat /proc/sys/vm/extra_free_kbytes 24300 本平台watermark_scale_factor的值为10console:/ # cat /proc/sys/vm/watermark_scale_factor 10Android为什么要增加extra_free_kbytes的值呢,主要目的是为了拉开watermark[WMARK_LOW]和watermark[WMARK_MIN]的距离。下面是我从本地的ubuntu开发机截取的zoneinfo信息,可以看到,min和low的差值并不大,其中low是min的1.25倍,high是min的1.5倍。Node 0, zone DMA ...... pages free 3977 min 16 low 20 high 24 spanned 4095 present 3998 managed 3977 protection: (0, 3116, 15719, 15719, 15719) ...... Node 0, zone DMA32 pages free 417377 min 3346 low 4182 high 5018 spanned 1044480 present 825004 managed 808543 protection: (0, 0, 12602, 12602, 12602) ......根据上图可知我们分配页的第一次尝试是从LOW水位开始分配的,当所剩余的空闲页小于LOW水位的时候,就会唤醒kswapd内核线程进行内存回收如果回收内存效果很显著,当空闲页大于HIGH水位的时候,则会停止kswapd内核线程回收如果回收内存效果不明显,当空闲内存直接小于MIN水位的时候,则会进行直接的内存回收(Direct reclaim),这样空闲内存就会逐渐增大当回收效果依然不明显的时候,则会启动OOM杀死进程kswapd周期回收机制kswapd是linux中用于页面回收的内核线程。当空闲内存的值低于low时,内存面临着一定的压力,在这次分配结束后kswapd就会被唤醒,这时内核线程kswapd开始进行页面回收,当kswapd回收页面发现此时内存终于到达了high水位,那么系统认为内存已经不再紧张了,所以将会停止进一步的操作。要注意,在这种情况下,内存分配虽然会触发内存回收,但不存在被内存回收所阻塞的问题,两者的执行关系是异步的。这里所说的“空闲内存”其实是一个zone总的空闲内存减去其lowmem_reserve的值。对于kswapd来说,要回收多少内存才算完成任务呢?只要把空闲内存的大小恢复到high对应的watermark值就可以了,当然,这取决于当前空闲内存和high值之间的差距,差距越大,需要回收的内存也就越多。low可以被认为是一个警戒水位线,而high则是一个安全的水位线。内存紧缺直接回收机制如果内存达到或者低于min时,这时说明现在内存严重不足,会触发内核直接回收操作(direct reclaim),这是一种默认的操作,此时分配器将同步等待内存回收完成,再进行内存分配。还有一种特殊情况,如果内存分配的请求是带了PF_MEMALLOC标志位的,并且现在空闲内存的大小可以满足本次内存分配的需求,那么也将是先分配,再回收。使用PF_MEMALLOC(PF表示per-process flag)相当于是忽略了watermark,因此它对应的内存分配的标志是ALLOC_NO_WATERMARk。能够获取"min"值以下的内存,也意味着该process有动用几乎所有内存的权力,因此它也对应GFP的标志__GFP_MEMALLOC。if (gfp_mask & __GFP_MEMALLOC) return ALLOC_NO_WATERMARKS; if (alloc_flags & ALLOC_NO_WATERMARKS) set_page_pfmemalloc(page); 可在内存严重短缺的时候,拥有不等待回收而强行分配内存的权力的进程其实可以想到kswapd,因为kswapd本身就是负责回收内存的,它只需要占用一小部分内存支撑其正常运行,就可以去回收更多的内存。虽然kswapd是在low到min的这段区间被唤醒加入调度队列的,但当它真正执行的时候,空闲内存的值可能已经掉到min以下了。可见,min值存在得一个意义是保证像kswapd这样得特殊任务能够在需要得时候立刻获取所需得内存。比如下面ubunut的水位,其中min=16, low=20, high=24比如当前空闲内存是在LOW水位以及MIN以上,这时候后台会启动kswapd内核线程进行进程内存回收,假设这时候突然有个很大的进程需要很大的内存请求,这样一来kswapd回收速度赶不上分配速度,内存一下掉到了MIN水位,这样直接就触发了直接内存回收,直接回收很影响系统性能的。这样看来linux原生的代码涉及MIN-LOW之间的间隙太小,很容易导致进入直接回收的情况的。所以在android的版本上增加了一个变量extra_free_kbytes.
-



![[转载]linux 复合页( Compound Page )的介绍](https://adtxl.com/usr/themes/Joe/assets/thumb/34.jpg)