搜索到
110
篇与
的结果
-
 thermal代码分析(1)Makefile文件 # # Makefile for sensor chip drivers. # obj-$(CONFIG_THERMAL) += thermal_sys.o thermal_sys-y += thermal_core.o #核心代码 # interface to/from other layers providing sensors thermal_sys-$(CONFIG_THERMAL_HWMON) += thermal_hwmon.o thermal_sys-$(CONFIG_THERMAL_OF) += of-thermal.o #dts解析 # governors 五种governor thermal_sys-$(CONFIG_THERMAL_GOV_FAIR_SHARE) += fair_share.o thermal_sys-$(CONFIG_THERMAL_GOV_BANG_BANG) += gov_bang_bang.o thermal_sys-$(CONFIG_THERMAL_GOV_STEP_WISE) += step_wise.o thermal_sys-$(CONFIG_THERMAL_GOV_USER_SPACE) += user_space.o thermal_sys-$(CONFIG_THERMAL_GOV_POWER_ALLOCATOR) += power_allocator.o # cpufreq cooling thermal_sys-$(CONFIG_CPU_THERMAL) += cpu_cooling.o # clock cooling thermal_sys-$(CONFIG_CLOCK_THERMAL) += clock_cooling.o # devfreq cooling thermal_sys-$(CONFIG_DEVFREQ_THERMAL) += devfreq_cooling.o # platform thermal drivers 平台相关代码,提供读取温度的接口 obj-$(CONFIG_QCOM_SPMI_TEMP_ALARM) += qcom-spmi-temp-alarm.o obj-$(CONFIG_SPEAR_THERMAL) += spear_thermal.o obj-$(CONFIG_ROCKCHIP_THERMAL) += rockchip_thermal.o obj-$(CONFIG_RCAR_THERMAL) += rcar_thermal.o obj-$(CONFIG_KIRKWOOD_THERMAL) += kirkwood_thermal.o obj-y += samsung/ obj-$(CONFIG_DOVE_THERMAL) += dove_thermal.o obj-$(CONFIG_DB8500_THERMAL) += db8500_thermal.o obj-$(CONFIG_ARMADA_THERMAL) += armada_thermal.o obj-$(CONFIG_TANGO_THERMAL) += tango_thermal.o obj-$(CONFIG_IMX_THERMAL) += imx_thermal.o obj-$(CONFIG_MAX77620_THERMAL) += max77620_thermal.o obj-$(CONFIG_QORIQ_THERMAL) += qoriq_thermal.o obj-$(CONFIG_DB8500_CPUFREQ_COOLING) += db8500_cpufreq_cooling.o obj-$(CONFIG_INTEL_POWERCLAMP) += intel_powerclamp.o obj-$(CONFIG_X86_PKG_TEMP_THERMAL) += x86_pkg_temp_thermal.o obj-$(CONFIG_INTEL_SOC_DTS_IOSF_CORE) += intel_soc_dts_iosf.o obj-$(CONFIG_INTEL_SOC_DTS_THERMAL) += intel_soc_dts_thermal.o obj-$(CONFIG_INTEL_QUARK_DTS_THERMAL) += intel_quark_dts_thermal.o obj-$(CONFIG_TI_SOC_THERMAL) += ti-soc-thermal/ obj-$(CONFIG_INT340X_THERMAL) += int340x_thermal/ obj-$(CONFIG_INTEL_BXT_PMIC_THERMAL) += intel_bxt_pmic_thermal.o obj-$(CONFIG_INTEL_PCH_THERMAL) += intel_pch_thermal.o obj-$(CONFIG_ST_THERMAL) += st/ obj-$(CONFIG_QCOM_TSENS) += qcom/ obj-$(CONFIG_TEGRA_SOCTHERM) += tegra/ obj-$(CONFIG_HISI_THERMAL) += hisi_thermal.o obj-$(CONFIG_MTK_THERMAL) += mtk_thermal.o obj-$(CONFIG_GENERIC_ADC_THERMAL) += thermal-generic-adc.o
thermal代码分析(1)Makefile文件 # # Makefile for sensor chip drivers. # obj-$(CONFIG_THERMAL) += thermal_sys.o thermal_sys-y += thermal_core.o #核心代码 # interface to/from other layers providing sensors thermal_sys-$(CONFIG_THERMAL_HWMON) += thermal_hwmon.o thermal_sys-$(CONFIG_THERMAL_OF) += of-thermal.o #dts解析 # governors 五种governor thermal_sys-$(CONFIG_THERMAL_GOV_FAIR_SHARE) += fair_share.o thermal_sys-$(CONFIG_THERMAL_GOV_BANG_BANG) += gov_bang_bang.o thermal_sys-$(CONFIG_THERMAL_GOV_STEP_WISE) += step_wise.o thermal_sys-$(CONFIG_THERMAL_GOV_USER_SPACE) += user_space.o thermal_sys-$(CONFIG_THERMAL_GOV_POWER_ALLOCATOR) += power_allocator.o # cpufreq cooling thermal_sys-$(CONFIG_CPU_THERMAL) += cpu_cooling.o # clock cooling thermal_sys-$(CONFIG_CLOCK_THERMAL) += clock_cooling.o # devfreq cooling thermal_sys-$(CONFIG_DEVFREQ_THERMAL) += devfreq_cooling.o # platform thermal drivers 平台相关代码,提供读取温度的接口 obj-$(CONFIG_QCOM_SPMI_TEMP_ALARM) += qcom-spmi-temp-alarm.o obj-$(CONFIG_SPEAR_THERMAL) += spear_thermal.o obj-$(CONFIG_ROCKCHIP_THERMAL) += rockchip_thermal.o obj-$(CONFIG_RCAR_THERMAL) += rcar_thermal.o obj-$(CONFIG_KIRKWOOD_THERMAL) += kirkwood_thermal.o obj-y += samsung/ obj-$(CONFIG_DOVE_THERMAL) += dove_thermal.o obj-$(CONFIG_DB8500_THERMAL) += db8500_thermal.o obj-$(CONFIG_ARMADA_THERMAL) += armada_thermal.o obj-$(CONFIG_TANGO_THERMAL) += tango_thermal.o obj-$(CONFIG_IMX_THERMAL) += imx_thermal.o obj-$(CONFIG_MAX77620_THERMAL) += max77620_thermal.o obj-$(CONFIG_QORIQ_THERMAL) += qoriq_thermal.o obj-$(CONFIG_DB8500_CPUFREQ_COOLING) += db8500_cpufreq_cooling.o obj-$(CONFIG_INTEL_POWERCLAMP) += intel_powerclamp.o obj-$(CONFIG_X86_PKG_TEMP_THERMAL) += x86_pkg_temp_thermal.o obj-$(CONFIG_INTEL_SOC_DTS_IOSF_CORE) += intel_soc_dts_iosf.o obj-$(CONFIG_INTEL_SOC_DTS_THERMAL) += intel_soc_dts_thermal.o obj-$(CONFIG_INTEL_QUARK_DTS_THERMAL) += intel_quark_dts_thermal.o obj-$(CONFIG_TI_SOC_THERMAL) += ti-soc-thermal/ obj-$(CONFIG_INT340X_THERMAL) += int340x_thermal/ obj-$(CONFIG_INTEL_BXT_PMIC_THERMAL) += intel_bxt_pmic_thermal.o obj-$(CONFIG_INTEL_PCH_THERMAL) += intel_pch_thermal.o obj-$(CONFIG_ST_THERMAL) += st/ obj-$(CONFIG_QCOM_TSENS) += qcom/ obj-$(CONFIG_TEGRA_SOCTHERM) += tegra/ obj-$(CONFIG_HISI_THERMAL) += hisi_thermal.o obj-$(CONFIG_MTK_THERMAL) += mtk_thermal.o obj-$(CONFIG_GENERIC_ADC_THERMAL) += thermal-generic-adc.o -
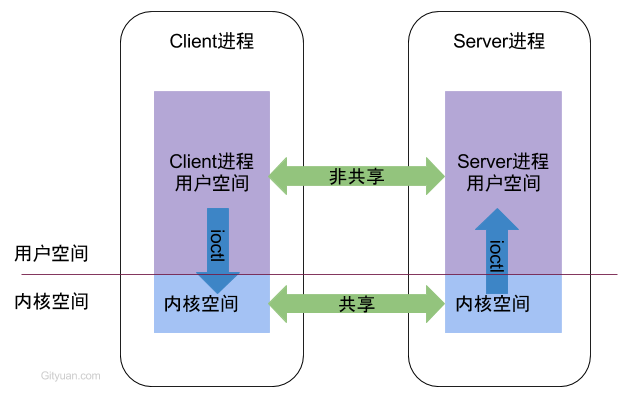
Android Binder机制(1)简介 [TOC]1. 概述Android系统中,每个应用程序是由Android的Activity,Service,Broadcast,ContentProvider这四剑客的中一个或多个组合而成,这四剑客所涉及的多进程间的通信底层都是依赖于Binder IPC机制。例如当进程A中的Activity要向进程B中的Service通信,这便需要依赖于Binder IPC。不仅于此,整个Android系统架构中,大量采用了Binder机制作为IPC(进程间通信)方案,当然也存在部分其他的IPC方式,比如Zygote通信便是采用socket。Binder作为Android系统提供的一种IPC机制,无论从事系统开发还是应用开发,都应该有所了解,这是Android系统中最重要的组成,也是最难理解的一块知识点,错综复杂。要深入了解Binder机制,最好的方法便是阅读源码,借用Linux鼻祖Linus Torvalds曾说过的一句话:Read The Fucking Source Code。2. Binder2.1 IPC原理从进程角度来看IPC机制每个Android的进程,只能运行在自己进程所拥有的虚拟地址空间。对应一个4GB的虚拟地址空间,其中3GB是用户空间,1GB是内核空间,当然内核空间的大小是可以通过参数配置调整的。对于用户空间,不同进程之间彼此是不能共享的,而内核空间却是可共享的。Client进程向Server进程通信,恰恰是利用进程间可共享的内核内存空间来完成底层通信工作的,Client端与Server端进程往往采用ioctl等方法跟内核空间的驱动进行交互。2.2 Binder原理Binder通信采用C/S架构,从组件视角来说,包含Client、Server、ServiceManager以及Binder驱动,其中Service Manager用于管理系统中的各种服务。架构图如下所示:可以看出无论是注册服务和获取服务的过程都需要ServiceManager,需要注意的是此处的Service Manager是指Native层的ServiceManager(C++),并非指framework层的ServiceManager(Java)。ServiceManager是整个Binder通信机制的大管家,是Android进程间通信机制Binder的守护进程,要掌握Binder机制,首先需要了解系统是如何首次启动Service Manager。当Service Manager启动之后,Client端和Server端通信时都需要先获取Service Manager接口,才能开始通信服务。图中Client/Server/ServiceManage之间的相互通信都是基于Binder机制。既然基于Binder机制通信,那么同样也是C/S架构,则图中的3大步骤都有相应的Client端与Server端。注册服务(addService):Server进程要先注册Service到ServiceManager。该过程:Server是客户端,ServiceManager是服务端。获取服务(getService):Client进程使用某个Service前,须先向ServiceManager中获取相应的Service。该过程:Client是客户端,ServiceManager是服务端。使用服务:Client根据得到的Service信息建立与Service所在的Server进程通信的通路,然后就可以直接与Service交互。该过程:client是客户端,server是服务端。图中的Client,Server,Service Manager之间交互都是虚线表示,是由于它们彼此之间不是直接交互的,而是都通过与Binder驱动进行交互的,从而实现IPC通信方式。其中Binder驱动位于内核空间,Client,Server,Service Manager位于用户空间。Binder驱动和Service Manager可以看做是Android平台的基础架构,而Client和Server是Android的应用层,开发人员只需自定义实现client、Server端,借助Android的基本平台架构便可以直接进行IPC通信。2.3 C/S模式BpBinder(客户端)和BBinder(服务端)都是Android中Binder通信相关的代表,它们都从IBinder类中派生而来,关系图如下:client端:BpBinder.transact()来发送事务请求;server端:BBinder.onTransact()会接收到相应事务。转载:http://gityuan.com/2015/10/31/binder-prepare/
-
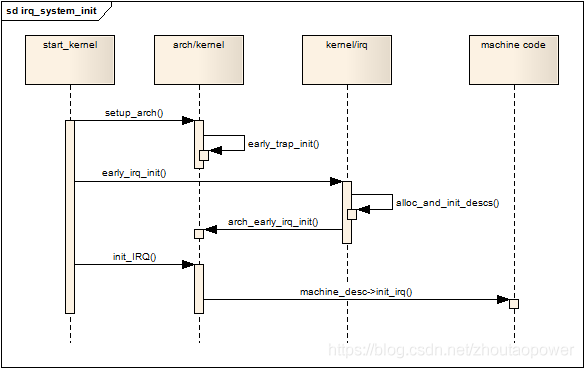
Linux内核中断机制 [TOC]1. 中断的概念中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的 CPU 暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。Linux中通常分为外部中断(又叫硬件中断)和内部中断(又叫异常)。当 CPU 收到一个中断 (IRQ)的时候,会去执行该中断对应的处理函数(ISR)。普通情况下,会有一个中断向量表,向量表中定义了 CPU 对应的每一个外设资源的中断处理程序的入口,当发生对应的中断的时候, CPU 直接跳转到这个入口执行程序。也就是中断上下文。(注意:中断上下文中,不可阻塞睡眠)。2. Linux中断 top/bottom玩过 MCU 的人都知道,中断服务程序的设计最好是快速完成任务并退出,因为此刻系统处于被中断中。但是在 ISR 中又有一些必须完成的事情,比如:清中断标志,读/写数据,寄存器操作等。在 Linux 中,同样也是这个要求,希望尽快的完成 ISR。但事与愿违,有些 ISR 中任务繁重,会消耗很多时间,导致响应速度变差。Linux 中针对这种情况,将中断分为了两部分:上半部(top half):收到一个中断,立即执行,有严格的时间限制,只做一些必要的工作,比如:应答,复位等。这些工作都是在所有中断被禁止的情况下完成的。底半部(bottom half):能够被推迟到后面完成的任务会在底半部进行。在适合的时机,下半部会被开中断执行。3. 中断处理程序驱动程序可以使用接口:request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev)参数含义irq表了该中断的中断号,一般 CPU 的中断号都会事先定义好。handler中断发生后的 ISRflags中断标志( IRQF_DISABLED / IRQFSAMPLE_RANDOM / IRQF_TIMER / IRQF_SHARED)name中断相关的设备 ASCII 文本,例如 "keyboard",这些名字会在 /proc/irq 和 /proc/interrupts 文件使用dev用于共享中断线,传递驱动程序的设备结构。非共享类型的中断,直接设置成为 NULL中断标志flag的含义:标志含义IRQF_DISABLED设置这个标志的话,意味着内核在处理这个 ISR 期间,要禁止其他中断(多数情况不使用这个)IRQFSAMPLE_RANDOM表明这个设备产生的中断对内核熵池有贡献IRQF_TIMER为系统定时器准备的标志IRQF_SHARED表明多个中断处理程序之间共享中断线。同一个给定的线上注册每个处理程序,必须设置这个调用request_irq成功执行返回0。常见错误是 -EBUSY,表示给定的中断线已经在使用(或者没有指定 IRQF_SHARED)注意:request_irq 函数可能引起睡眠,所以不允许在中断上下文或者不允许睡眠的代码中调用。Linux内核熵池:Linux内核采用熵来描述数据的随机性。熵(entropy)是描述系统混乱无序程度的物理量,一个系统的熵越大则说明该系统的有序性越差,即不确定性越大。在信息学中,熵被用来表征一个符号或系统的不确定性,熵越大,表明系统所含有用信息量越少,不确定度越大。计算机本身是可预测的系统,因此,用计算机算法不可能产生真正的随机数。但是机器的环境中充满了各种各样的噪声,如硬件设备发生中断的时间,用户点击鼠标的时间间隔等是完全随机的,事先无法预测。Linux内核实现的随机数产生器正是利用系统中的这些随机噪声来产生高质量随机数序列。核维护了一个熵池用来收集来自设备驱动程序和其它来源的环境噪音。理论上,熵池中的数据是完全随机的,可以实现产生真随机数序列。为跟踪熵池中数据的随机性,内核在将数据加入池的时候将估算数据的随机性,这个过程称作熵估算。熵估算值描述池中包含的随机数位数,其值越大表示池中数据的随机性越好。释放中断:const void *free_irq(unsigned int irq, void *dev_id)用于释放中断处理函数。注意:Linux 中的中断处理程序是无须重入的。当给定的中断处理程序正在执行的时候,其中断线在所有的处理器上都会被屏蔽掉,以防在同一个中断线上又接收到另一个新的中断。通常情况下,除了该中断的其他中断都是打开的,也就是说其他的中断线上的重点都能够被处理,但是当前的中断线总是被禁止的,故,同一个中断处理程序是绝对不会被自己嵌套的。4. 中断上下文与进程上下文不一样,内核执行中断服务程序的时候,处于中断上下文。中断处理程序并没有自己的独立的栈,而是使用了内核栈,其大小一般是有限制的(32bit 机器 8KB)。所以其必须短小精悍。同时中断服务程序是打断了正常的程序流程,这一点上也必须保证快速的执行。同时中断上下文中是不允许睡眠,阻塞的。中断上下文不能睡眠的原因是:1、 中断处理的时候,不应该发生进程切换,因为在中断context中,唯一能打断当前中断handler的只有更高优先级的中断,它不会被进程打断,如果在 中断context中休眠,则没有办法唤醒它,因为所有的wake_up_xxx都是针对某个进程而言的,而在中断context中,没有进程的概念,没 有一个task_struct(这点对于softirq和tasklet一样),因此真的休眠了,比如调用了会导致block的例程,内核几乎肯定会死。2、schedule()在切换进程时,保存当前的进程上下文(CPU寄存器的值、进程的状态以及堆栈中的内容),以便以后恢复此进程运行。中断发生后,内核会先保存当前被中断的进程上下文(在调用中断处理程序后恢复);但在中断处理程序里,CPU寄存器的值肯定已经变化了吧(最重要的程序计数器PC、堆栈SP等),如果此时因为睡眠或阻塞操作调用了schedule(),则保存的进程上下文就不是当前的进程context了.所以不可以在中断处理程序中调用schedule()。3、内核中schedule()函数本身在进来的时候判断是否处于中断上下文:if(unlikely(in_interrupt()))BUG();因此,强行调用schedule()的结果就是内核BUG。4、中断handler会使用被中断的进程内核堆栈,但不会对它有任何影响,因为handler使用完后会完全清除它使用的那部分堆栈,恢复被中断前的原貌。5、处于中断context时候,内核是不可抢占的。因此,如果休眠,则内核一定挂起。5. 举例比如 RTC 驱动程序 (drivers/char/rtc.c)。在 RTC 驱动的初始化阶段,会调用到 rtc_init 函数:module_init(rtc_init);在这个初始化函数中调用到了 request_irq 用于申请中断资源,并注册服务程序:static int __init rtc_init(void) { ... rtc_int_handler_ptr = rtc_interrupt; ... request_irq(RTC_IRQ, rtc_int_handler_ptr, 0, "rtc", NULL) ... }RTC_IRQ 是中断号,和处理器绑定。rtc_interrupt 是中断处理程序:static irqreturn_t rtc_interrupt(int irq, void *dev_id) { /* * Can be an alarm interrupt, update complete interrupt, * or a periodic interrupt. We store the status in the * low byte and the number of interrupts received since * the last read in the remainder of rtc_irq_data. */ spin_lock(&rtc_lock); rtc_irq_data += 0x100; rtc_irq_data &= ~0xff; if (is_hpet_enabled()) { /* * In this case it is HPET RTC interrupt handler * calling us, with the interrupt information * passed as arg1, instead of irq. */ rtc_irq_data |= (unsigned long)irq & 0xF0; } else { rtc_irq_data |= (CMOS_READ(RTC_INTR_FLAGS) & 0xF0); } if (rtc_status & RTC_TIMER_ON) mod_timer(&rtc_irq_timer, jiffies + HZ/rtc_freq + 2*HZ/100); spin_unlock(&rtc_lock); wake_up_interruptible(&rtc_wait); kill_fasync(&rtc_async_queue, SIGIO, POLL_IN); return IRQ_HANDLED; }每次收到 RTC 中断,就会调用进这个函数。6. 中断处理流程发生中断时,CPU执行异常向量vector_irq的代码, 即异常向量表中的中断异常的代码,它是一个跳转指令,跳去执行真正的中断处理程序,在vector_irq里面,最终会调用中断处理的总入口函数。C 语言的入口为 : asm_do_IRQ(unsigned int irq, struct pt_regs *regs)asmlinkage void __exception_irq_entry asm_do_IRQ(unsigned int irq, struct pt_regs *regs) { handle_IRQ(irq, regs); }该函数的入参 irq 为中断号。asm_do_IRQ -> handle_IRQvoid handle_IRQ(unsigned int irq, struct pt_regs *regs) { __handle_domain_irq(NULL, irq, false, regs); }handle_IRQ ->\_\_handle_domain_irqint __handle_domain_irq(struct irq_domain *domain, unsigned int hwirq, bool lookup, struct pt_regs *regs) { struct pt_regs *old_regs = set_irq_regs(regs); unsigned int irq = hwirq; int ret = 0; irq_enter(); #ifdef CONFIG_IRQ_DOMAIN if (lookup) irq = irq_find_mapping(domain, hwirq); #endif /* * Some hardware gives randomly wrong interrupts. Rather * than crashing, do something sensible. */ if (unlikely(!irq || irq >= nr_irqs)) { ack_bad_irq(irq); ret = -EINVAL; } else { generic_handle_irq(irq); } irq_exit(); set_irq_regs(old_regs); return ret; }这里请注意:先调用了 irq_enter 标记进入了硬件中断:irq\_enter是更新一些系统的统计信息,同时在\_\_irq_enter宏中禁止了进程的抢占。虽然在产生IRQ时,ARM会自动把CPSR中的I位置位,禁止新的IRQ请求,直到中断控制转到相应的流控层后才通过local_irq_enable()打开。那为何还要禁止抢占?这是因为要考虑中断嵌套的问题,一旦流控层或驱动程序主动通过local_irq_enable打开了IRQ,而此时该中断还没处理完成,新的irq请求到达,这时代码会再次进入irq\_enter,在本次嵌套中断返回时,内核不希望进行抢占调度,而是要等到最外层的中断处理完成后才做出调度动作,所以才有了禁止抢占这一处理再调用 generic\_handle\_irq最后调用 irq_exit 删除进入硬件中断的标记\_\_handle_domain_irq -> generic_handle_irqint generic_handle_irq(unsigned int irq) { struct irq_desc *desc = irq_to_desc(irq); if (!desc) return -EINVAL; generic_handle_irq_desc(desc); return 0; } EXPORT_SYMBOL_GPL(generic_handle_irq);首先在函数 irq_to_desc 中根据发生中断的中断号,去取出它的 irq_desc 中断描述结构,然后调用 generic_handle_irq_desc:static inline void generic_handle_irq_desc(struct irq_desc *desc) { desc->handle_irq(desc); }这里调用了 handle_irq 函数。所以,在上述流程中,还需要分析 irq_to_desc 流程:struct irq_desc *irq_to_desc(unsigned int irq) { return (irq < NR_IRQS) ? irq_desc + irq : NULL; } EXPORT_SYMBOL(irq_to_desc);NR_IRQS 是支持的总的中断个数,当然,irq 不能够大于这个数目。所以返回 irq_desc + irq。irq_desc 是一个全局的数组:struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = { [0 ... NR_IRQS-1] = { .handle_irq = handle_bad_irq, .depth = 1, .lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock), } };这里是这个数组的初始化的地方。所有的 handle_irq 函数都被初始化成为了 handle_bad_irq。细心的观众可能发现了,调用这个 desc->handle_irq(desc) 函数,并不是咱们注册进去的中断处理函数啊,因为两个函数的原型定义都不一样。这个 handle_irq 是 irq_flow_handler_t 类型,而我们注册进去的服务程序是 irq_handler_t,这两个明显不是同一个东西,所以这里我们还需要继续分析。6.1 中断相关的数据结构Linux中,与中断相关的数据结构有3个结构名称作用irq_descIRQ 的软件层面上的资源描述,用于描述IRQ线的属性与状态,被称为中断描述符。irqactionIRQ 的通用操作irq_chip对应每个芯片的具体实现,用于描述不同类型的中断控制器。irq_chip 是一串和芯片相关的函数指针,这里定义的非常的全面,基本上和 IRQ 相关的可能出现的操作都全部定义进去了,具体根据不同的芯片,需要在不同的芯片的地方去初始化这个结构,然后这个结构会嵌入到通用的 IRQ 处理软件中去使用,使得软件处理逻辑和芯片逻辑完全的分开。6.2 初始化Chip相关的IRQ众所周知,启动的时候,C 语言从 start_kernel 开始,在这里面,调用了和 machine 相关的 IRQ 的初始化 init_IRQ():asmlinkage __visible void __init start_kernel(void) { char *command_line; char *after_dashes; ..... early_irq_init(); init_IRQ(); ..... }在 init_IRQ 中,调用了 machine_desc->init_irq():void __init init_IRQ(void) { int ret; if (IS_ENABLED(CONFIG_OF) && !machine_desc->init_irq) irqchip_init(); else machine_desc->init_irq(); if (IS_ENABLED(CONFIG_OF) && IS_ENABLED(CONFIG_CACHE_L2X0) && (machine_desc->l2c_aux_mask || machine_desc->l2c_aux_val)) { if (!outer_cache.write_sec) outer_cache.write_sec = machine_desc->l2c_write_sec; ret = l2x0_of_init(machine_desc->l2c_aux_val, machine_desc->l2c_aux_mask); if (ret && ret != -ENODEV) pr_err("L2C: failed to init: %d\n", ret); } uniphier_cache_init(); }machine_desc->init_irq() 完成对中断控制器的初始化,为每个irq_desc结构安装合适的流控handler,为每个irq_desc结构安装irq_chip指针,使他指向正确的中断控制器所对应的irq_chip结构的实例,同时,如果该平台中的中断线有多路复用(多个中断公用一个irq中断线)的情况,还应该初始化irq_desc中相应的字段和标志,以便实现中断控制器的级联。这里初始化的时候回调用到具体的芯片相关的中断初始化的地方。int __init s5p_init_irq_eint(void) { int irq; for (irq = IRQ_EINT(0); irq <= IRQ_EINT(15); irq++) irq_set_chip(irq, &s5p_irq_vic_eint); for (irq = IRQ_EINT(16); irq <= IRQ_EINT(31); irq++) { irq_set_chip_and_handler(irq, &s5p_irq_eint, handle_level_irq); set_irq_flags(irq, IRQF_VALID); } irq_set_chained_handler(IRQ_EINT16_31, s5p_irq_demux_eint16_31); return 0; }而在这些里面,都回去调用类似于:void irq_set_chip_and_handler_name(unsigned int irq, struct irq_chip *chip, irq_flow_handler_t handle, const char *name); irq_set_handler(unsigned int irq, irq_flow_handler_t handle) { __irq_set_handler(irq, handle, 0, NULL); } static inline void irq_set_chained_handler(unsigned int irq, irq_flow_handler_t handle) { __irq_set_handler(irq, handle, 1, NULL); } void irq_set_chained_handler_and_data(unsigned int irq, irq_flow_handler_t handle, void *data); 这些函数定义在 include/linux/irq.h 文件。是对芯片初始化的时候可见的 APIs,用于指定中断“流控”中的 :irq_flow_handler_t handle也就是中断来的时候,最后那个函数调用。中断流控函数,分几种,电平触发的中断,边沿触发的等:/* * Built-in IRQ handlers for various IRQ types, * callable via desc->handle_irq() */ extern void handle_level_irq(struct irq_desc *desc); extern void handle_fasteoi_irq(struct irq_desc *desc); extern void handle_edge_irq(struct irq_desc *desc); extern void handle_edge_eoi_irq(struct irq_desc *desc); extern void handle_simple_irq(struct irq_desc *desc); extern void handle_untracked_irq(struct irq_desc *desc); extern void handle_percpu_irq(struct irq_desc *desc); extern void handle_percpu_devid_irq(struct irq_desc *desc); extern void handle_bad_irq(struct irq_desc *desc); extern void handle_nested_irq(unsigned int irq);而在这些处理函数里,会去调用到 : handle_irq_event 比如:/** * handle_level_irq - Level type irq handler * @desc: the interrupt description structure for this irq * * Level type interrupts are active as long as the hardware line has * the active level. This may require to mask the interrupt and unmask * it after the associated handler has acknowledged the device, so the * interrupt line is back to inactive. */ void handle_level_irq(struct irq_desc *desc) { raw_spin_lock(&desc->lock); mask_ack_irq(desc); if (!irq_may_run(desc)) goto out_unlock; desc->istate &= ~(IRQS_REPLAY | IRQS_WAITING); /* * If its disabled or no action available * keep it masked and get out of here */ if (unlikely(!desc->action || irqd_irq_disabled(&desc->irq_data))) { desc->istate |= IRQS_PENDING; goto out_unlock; } kstat_incr_irqs_this_cpu(desc); handle_irq_event(desc); cond_unmask_irq(desc); out_unlock: raw_spin_unlock(&desc->lock); }而这个 handle_irq_event 则是调用了处理,handle_irq_event_percpu:irqreturn_t handle_irq_event(struct irq_desc *desc) { irqreturn_t ret; desc->istate &= ~IRQS_PENDING; irqd_set(&desc->irq_data, IRQD_IRQ_INPROGRESS); raw_spin_unlock(&desc->lock); ret = handle_irq_event_percpu(desc); raw_spin_lock(&desc->lock); irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS); return ret; }handle_irq_event_percpu->\_\_handle_irq_event_percpu-> [action->handler()]这里终于看到了调用 的地方了,就是咱们通过 request_irq 注册进去的函数7. /proc/interrupts这个 proc 下放置了对应中断号的中断次数和对应的 dev-name参考:Linux 中断之中断处理浅析
-
线程与对称处理器 1. 进程和线程进程的概念有两个特点,一是资源所有权。一个进程包括一个存放进程映像的虚拟地址空间;二是调度/执行。一个进程沿着通过一个或多个程序的一条执行路径(轨迹)执行。这两个特点是独立的,为了区分这两个特点,分派的单位通常称作线程,而拥有资源所有权的单位称为进程。1.1 多线程在多线程环境中,进程被定义成资源分配的单位和一个被保护的单位,与进程相关联的有:存放进程映像的虚拟地址空间受保护地对处理器、其他进程(用于进程间通信)、文件和I/O资源的访问。在一个进程中,可能有一个或多个线程,每个线程有:线程执行状态(运行、就绪等)在未运行时保存的线程上下文;从某种意义上看,线程可以被看做进程内的一个被独立地操作的程序计数器一个执行栈用于每个线程局部变量的静态存储空间与进程内的其他线程共享的对进程的内存和资源的访问。线程的优点:在一个已有进程中创建一个新线程比创建一个全新进程所需的时间要少许多。研究表明,在UNIX中,线程的创建比进程快10倍终止一个线程比终止一个进程花费的时间少同一个进程内线程间切换比进程间切换花费的时间少线程提高了不同的执行程序间通信的效率。在大多数操作系统中,独立进程间的通信需要内核的介入,以提供保护和通信所需要的机制。但是,由于同一个进程中的线程共享内存和文件,它们无需调用内核就可以互相通信。
-
并发性:互斥与同步 操作系统设计中的核心问题是关于进程和线程的管理。并发是所有问题的基础,也是操作系统设计的基础。并发包括许多设计问题,其中有进程间通信、资源共享与竞争(例如内存、文件、I/O访问)、多个进程活动的同步以及分配给进程的处理器时间等。和并发相关的一些关键术语:原子操作一个或多个指令的序列,对外是不可分的;即没有其他进程可以看到其中间状态或者中断此操作临界区是一段代码,在这段代码中进程将访问共享资源,当另外一个进程已经在这段代码中运行时,这个进程就不能在这段代码中执行。死锁两个或两个以上的进程因其中的每个进程都在等待其他进程做完某些事情而不能继续执行,这样的情形叫做死锁活锁两个或两个以上进程为了响应其他进程中的变化而持续改变自己的状态但不做有用的工作,这样的情形叫做活锁互斥当一个进程在临界区访问共享资源时,其他进程不能进入该临界区访问任何共享资源,这种情形叫做互斥竞争条件多个线程或者进程在读写一个共享数据时,结果依赖于它们执行的相对时间,这种情形叫做竞争饥饿是指一个可运行的进程尽管可能继续执行,但被调度器无限期地忽视,而不能被调度执行的情况1.并发的原理在单处理器系统的情况下,出现问题的原因是中断可能会在进程中任何地方停止指令的执行;在多处理器系统的情况下,不仅同样的条件可以引发问题,而且当两个进程同时执行并且都试图访问同一个全局变量时,也会引发问题。这两类问题的解决方案是相同的:控制对共享资源的访问1.1 竞争条件竞争条件发生在多个进程或线程读写数据时,其最终的结果依赖于多个进程的指令执行顺序。1.2 操作系统关注的问题并发会带来哪些设计和管理问题?操作系统必须能够记住各个活跃的进程操作系统必须为每个进程分配和释放各种资源。操作系统必须保护每个进程的数据和物理资源,避免其他进程的无意干涉一个进程的功能和输出结果必须与执行速度无关。1.3 进程的交互知道程度关系一个进程对其他进程的影响潜在的控制问题进程之间不知道对方的存在竞争1.一个进程的结果与其他进程的活动无关 2.进程的执行时间可能会受影响互斥、死锁(可复用的资源)、饥饿进程间接知道对方的存在(如共享对象)通过共享合作1.一个进程的结果可能依赖于从其他进程获得的信息 2.进程的执行时间可能会受到影响互斥、死锁(可复用的资源)、饥饿、数据一致性进程直接知道对方的存在(它们有可用的通信原语)通过通信合作1.一个进程的结果可能依赖于从其他进程获得的信息2.进程的计时可能会受到影响死锁(可消费的资源)、饥饿2. 信号量现在讨论操作系统和用于提供并发性的程序设计语言机制。基本原理:两个或多个进程可以通过简单的信号进行合作,一个进程可以被迫在某一位置停止,直到它接收到一个特定的信号。任何复杂的合作需求都可以通过适当的信号结构得到满足,为了发信号,需要使用一个被称作信号量的特殊变量。为通过信号量s发送信号,进程可执行原语semSignal(s)(V操作);为通过信号量s接收信号,进程可执行原语semWait(s)(P操作);如果相应的信号仍然没有发送,则进程被挂起,直到发送完为止。为了达到预期的效果,可以把信号量看做是一个具有整数值的变量,在它之上定义三个操作:1)一个信号量可以初始化成非负数2)semWait操作使信号量减1。如果值变成负数,则执行semWait的进程被阻塞。否则进程继续执行。3)semSignal操作使信号量加1。如果值小于或者等于零,则被semWait操作阻塞的进程被解除阻塞。除了这三种操作外,没有任何其他方法可以检查或操作信号量。解释:开始时,信号量的值为零或正数。如果该值为正数,则该值等于发出semWait操作后可立即继续执行的进程的数量。如果该值为零(或者由于初始化,或者由于有等于信号量初值的进程已经等待),则发出semWait操作的下一个进程会被阻塞,此时该信号量的值变为负值。之后,每个后续的semWait操作都会使信号量的负值更大。该负值等于正在等待接触阻塞的进程的数量。在信号量为负值的情形下,每一个semSignal操作都会将等待进程中的一个进程解除阻塞。在信号量为负值的情形下,每一个semSignal操作都会将等待进程中的一个进程解除阻塞。2.1 互斥使用信号量s解决互斥问题的方法。设有n个进程,用数组P(i)表示,所有的进程都需要访问共享资源。每个进程中进入临界区前执行semWait(s),如果s的值为负,则进程被挂起;如果值为1,则s被减为0,进程立即进入临界区;由于s值不再为正,因而其他任何进程都不能进入临界区。/* program mutualexeclusion */ const int n = /* 进程数 */; semaphore s = 1; void P(int i) { while(true){ semWait(s); /* 临界区 */ semSignal(s); /* 其他部分 */ } } void main() { parbegin(P(1), P(2), ..., P(n)); }
-
-
(1)进程内存管理初探 [TOC]随着cpu技术发展,现在大部分移动设备、PC、服务器都已经使用上64bit的CPU,但是关于Linux内核的虚拟内存管理,还停留在历史的用户态与内核态虚拟内存3:1的观念中,导致在解决一些内存问题时存在误解。例如现在主流的移动设备操作系统Android,经常遇到进程使用大量内存导致被lmk杀死,分配不到内存而触发OOM/ANR,或者分配内存慢导致卡顿,内核态使用哪个分配内存的函数更合理等问题,有些涉及物理内存分配,有些涉及虚拟内存分配,如果不熟悉虚拟内存管理的技术知识,可能走很多弯路。本章节结合代码介绍进程虚拟内存布局以及进程的虚拟内存分配释放流程,涉及的代码是android-8.1, 内核版本kernel-4.9,架构是arm64。1. 几种地址的概念1.1 物理地址每片物理内存存储实际地址,例如一个8GB的内存,0x00000000表示第一个byte的地址,而0xFFFFFFFF表示的是最后一个byte的地址;物理地址的值与实际的内存条上的地址一一对应,物理地址的大小与cpu访问物理内存的总线宽度有一定的关系。1.2 线性地址为了保证系统多任务运行的安全性和可靠性(防止一个任务篡改系统或者其他任务的内存),CPU增加段页式内存管理;段基地址+段内偏移构成的地址就是线性地址;如果开启的分页内存管理,线性地址还要通过MMU计算才能转换出物理地址。1.3 逻辑地址每个进程运行时CPU看到的地址就是逻辑地址,实际上也是线性地址中的段内偏移地址,逻辑地址与段基地址可以计算出线性地址。进程在访问虚拟地址空间的任意合法地址时,都要按照逻辑地址->线性地址->物理地址的顺序换算才能找到对应的物理地址;由于段式内存管理存在性能、访问效率的问题,以及Linux要兼容各种CPU,在Linux内核中所有的用户态进程使用的同一个段,且段基地址都是0,如此既可以兼容的传统的段式内存管理,又可以通过页式内存映射更灵活的管理内存。由于同一个段基地址都是0,对每个进程来说,逻辑地址和线性地址是一样的;同时每个进程的PGD是不一样的,从而保证每个进程之间隔离,不同进程同一个虚拟地址映射的物理地址就不一样了。Linux系统采用延迟分配物理内存的策略,用户态进程每次分配内存时分配的都是虚拟内存,表示一段地址空间已经分配出来供进程使用;当进程第一次访问虚拟地址时,才会发现虚拟地址没有对应的物理内存,系统默认会触发缺页异常,从内核物理内存管理系统中分配物理页,建立页表中把虚拟地址映射到物理地址。对于缺页异常处理流程,页表创建/建立/销毁等操作在以后文章中介绍。2. 进程虚拟内存空间分布理论上,64bit地址支持访问的地址空间是[0, 2(64-1)],而实际上现有的应用程序都不会用这么大的地址空间,并且arm64芯片现在也不支持访问这么大的地址空间,arm64架构芯片最大支持访问48bit的地址空间。例如在Android系统中,整个虚拟地址空间分成两部分,如下图所示:其中[0x0001000000000000,0xFFFF000000000000]之间的地址是不规范地址,不能使用;该段内存把整个虚拟地址空间划分为两段,低段内存为进程用户态地址空间,高段内存为内核地址空间。参考代码arch\arm64\include\asm\memory.h):#define VA_BITS (CONFIG_ARM64_VA_BITS) #define VA_START (UL(0xffffffffffffffff)) << VA_BITS) #define PAGE_OFFSET (UL(0xffffffffffffffff)) << (VA_BITS - 1 )) 如果内核打开CONFIG_COMPAT选项,说明用户态既支持64位进程,也支持32位进程;由于32bit的地址最多可以访问的虚拟地址空间最多只有4GB,所以32位进程的用户态进程地址空间与64位进程是有区别的。32位进程的用户态地址空间是[0x0, 0x00000000FFFF_FFFF]64位进程的用户态地址空间是[0x0, 0x0000FFFFFFFF_FFFF]从代码看出,32bit进程用户空间大小是4GB,64bit进程的虚拟内存大小与CONFIG_ARM64_VA_BITS的值相关;如果CONFIG_ARM64_VA_BITS是48bit则可以达到256TB,现在的移动设备显然用不到这么大的内存空间,所以大部分Android设备中CONFIG_ARM64_VA_BITS默认配置的是39,即64bit进程的最大虚拟地址空间大小是512GB。虽然32bit或者64bit的进程在用户态内存空间大小不一样,但是当它们陷入到内核态后,访问的内核空间地址是没有差异的,都是从VA_START开始,直到0xFFFFFFFFFFFFFFFF结束,也是512GB。每个进程的虚拟地址空间主要分为如下几个区域(如图):参考:https://cloud.tencent.com/developer/article/1647582http://www.360doc.com/content/13/0915/09/8363527_314549128.shtml
-
c语言之va_list详解 [TOC]转载:https://blog.csdn.net/zhyjunfov/article/details/12017697一、介绍VA函数(variable argument function),参数个数可变函数,又称可变参数函数。C/C++编程中,系统提供给编程人员的va函数很少。printf()/scanf()系列函数,用于输入输出时格式化字符串;exec()系列函数,用于在程序中执行外部文件(main(int argc, char* argv[]算不算呢,与其说main()也是一个可变参数函数,倒不如说它是exec()经过封装后的具备特殊功能和意义的函数,至少在原理这一级上有很多相似之处)。由于参数个数的不确定,使va函数具有很大的灵活性,易用性,对没有使用过可变参数函数的编程人员很有诱惑力;那么,该如何编写自己的va函数,va函数的运用时机、编译实现又是如何。作者借本文谈谈自己关于va函数的一些浅见。二、从printf函数开始从大家都很熟悉的格式化字符串函数开始介绍可变参数函数。原型:int printf(const char * format, ...);参数format表示如何来格式字符串的指令,…表示可选参数,调用时传递给"..."的参数可有可无,根据实际情况而定。系统提供了vprintf系列格式化字符串的函数,用于编程人员封装自己的I/O函数。int vprintf / vscanf(const char * format, va_list ap); // 从标准输入/输出格式化字符串 int vfprintf / vfsacanf(FILE * stream, const char * format, va_list ap); // 从文件流 int vsprintf / vsscanf(char * s, const char * format, va_list ap); // 从字符串例1:格式化到一个文件流,可用于日志文件FILE *logfile; int WriteLog(const char * format, ...) { va_list arg_ptr; va_start(arg_ptr, format); int nWrittenBytes = vfprintf(logfile, format, arg_ptr); va_end(arg_ptr); return nWrittenBytes; } …调用时,与使用printf()没有区别。WriteLog("%04d-%02d-%02d %02d:%02d:%02d %s/%04d logged out.", nYear, nMonth, nDay, nHour, nMinute, szUserName, nUserID);同理,也可以从文件中执行格式化输入;或者对标准输入输出,字符串执行格式化。在上面的例1中,WriteLog()函数可以接受参数个数可变的输入,本质上,它的实现需要vprintf()的支持。如何真正实现属于自己的可变参数函数,包括控制每一个传入的可选参数。三、va函数的定义和va宏C语言支持va函数,作为C语言的扩展--C++同样支持va函数,但在C++中并不推荐使用,C++引入的多态性同样可以实现参数个数可变的函数。不过,C++的重载功能毕竟只能是有限多个可以预见的参数个数。比较而言,C中的va函数则可以定义无穷多个相当于C++的重载函数,这方面C++是无能为力的。va函数的优势表现在使用的方便性和易用性上,可以使代码更简洁。C编译器为了统一在不同的硬件架构、硬件平台上的实现,和增加代码的可移植性,提供了一系列宏来屏蔽硬件环境不同带来的差异。ANSI C标准下,va的宏定义在stdarg.h中,它们有:va_list,va_start(),va_arg(),va_end()。例2:求任意个自然数的平方和:int SqSum(int n1, ...) { va_list arg_ptr; int nSqSum = 0, n = n1; va_start(arg_ptr, n1); while (n > 0) { nSqSum += (n * n); n = va_arg(arg_ptr, int); } va_end(arg_ptr); return nSqSum; } // 调用时 int nSqSum = SqSum(7, 2, 7, 11, -1);可变参数函数的原型声明格式为:type VAFunction(type arg1, type arg2, … );参数可以分为两部分:个数确定的固定参数和个数可变的可选参数。函数至少需要一个固定参数,固定参数的声明和普通函数一样;可选参数由于个数不确定,声明时用"…"表示。固定参数和可选参数公同构成一个函数的参数列表。借助上面这个简单的例2,来看看各个va_xxx的作用。 va_list arg_ptr:定义一个指向个数可变的参数列表指针;va_start(arg_ptr, argN):使参数列表指针arg_ptr指向函数参数列表中的第一个可选参数说明:argN是位于第一个可选参数之前的固定参数,(或者说,最后一个固定参数;…之前的一个参数),函数参数列表中参数在内存中的顺序与函数声明时的顺序是一致的。如果有一va函数的声明是void va_test(char a, char b, char c, …),则它的固定参数依次是a,b,c,最后一个固定参数argN为c,因此就是va_start(arg_ptr, c)。va_arg(arg_ptr, type):返回参数列表中指针arg_ptr所指的参数,返回类型为type,并使指针arg_ptr指向参数列表中下一个参数。va_copy(dest, src):dest,src的类型都是va_list,va_copy()用于复制参数列表指针,将dest初始化为src。va_end(arg_ptr):清空参数列表,并置参数指针arg_ptr无效。说明:指针arg_ptr被置无效后,可以通过调用va_start()、va_copy()恢复arg_ptr。每次调用va_start() / va_copy()后,必须得有相应的va_end()与之匹配。参数指针可以在参数列表中随意地来回移动,但必须在va_start() … va_end()之内。四、编译器如何实现va例2中调用SqSum(7, 2, 7, 11, -1)来求7, 2, 7, 11的平方和,-1是结束标志。简单地说,va函数的实现就是对参数指针的使用和控制。typedef char * va_list; // x86平台下va_list的定义函数的固定参数部分,可以直接从函数定义时的参数名获得;对于可选参数部分,先将指针指向第一个可选参数,然后依次后移指针,根据与结束标志的比较来判断是否已经获得全部参数。因此,va函数中结束标志必须事先约定好,否则,指针会指向无效的内存地址,导致出错。这里,移动指针使其指向下一个参数,那么移动指针时的偏移量是多少呢,没有具体答案,因为这里涉及到内存对齐(alignment)问题,内存对齐跟具体使用的硬件平台有密切关系,比如大家熟知的32位x86平台规定所有的变量地址必须是4的倍数(sizeof(int) = 4)。va机制中用宏_INTSIZEOF(n)来解决这个问题,没有这些宏,va的可移植性无从谈起。首先介绍宏_INTSIZEOF(n),它求出变量占用内存空间的大小,是va的实现的基础。#define _INTSIZEOF(n) ((sizeof(n)+sizeof(int)-1)&~(sizeof(int) - 1) ) #define va_start(ap,v) ( ap = (va_list)&v + _INTSIZEOF(v) ) //第一个可选参数地址 #define va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) ) //下一个参数地址 #define va_end(ap) ( ap = (va_list)0 ) // 将指针置为无效下表是针对函数int TestFunc(int n1, int n2, int n3, …) 参数传递时的内存堆栈情况。(C编译器默认的参数传递方式是__cdecl。)对该函数的调用为int result = TestFunc(a, b, c, d. e); 其中e为结束标志。va_xxx宏如此编写的原因。1. va_start。为了得到第一个可选参数的地址,我们有三种办法可以做到:A) = &n3 + _INTSIZEOF(n3) // 最后一个固定参数的地址 + 该参数占用内存的大小B) = &n2 + _INTSIZEOF(n3) + _INTSIZEOF(n2) // 中间某个固定参数的地址 + 该参数之后所有固定参数占用的内存大小之和C) = &n1 + _INTSIZEOF(n3) + _INTSIZEOF(n2) + _INTSIZEOF(n1) // 第一个固定参数的地址 + 所有固定参数占用的内存大小之和从编译器实现角度来看,方法B),方法C)为了求出地址,编译器还需知道有多少个固定参数,以及它们的大小,没有把问题分解到最简单,所以不是很聪明的途径,不予采纳;相对来说,方法A)中运算的两个值则完全可以确定。va_start()正是采用A)方法,接受最后一个固定参数。调用va_start()的结果总是使指针指向下一个参数的地址,并把它作为第一个可选参数。在含多个固定参数的函数中,调用va_start()时,如果不是用最后一个固定参数,对于编译器来说,可选参数的个数已经增加,将给程序带来一些意想不到的错误。(当然如果你认为自己对指针已经知根知底,游刃有余,那么,怎么用就随你,你甚至可以用它完成一些很优秀(高效)的代码,但是,这样会大大降低代码的可读性。)注意:宏va_start是对参数的地址进行操作的,要求参数地址必须是有效的。一些地址无效的类型不能当作固定参数类型。比如:寄存器类型,它的地址不是有效的内存地址值;数组和函数也不允许,他们的长度是个问题。因此,这些类型时不能作为va函数的参数的。2. va_arg身兼二职:返回当前参数,并使参数指针指向下一个参数。初看va_arg宏定义很别扭,如果把它拆成两个语句,可以很清楚地看出它完成的两个职责。#define va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) ) //下一个参数地址 // 将( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )拆成: /* 指针ap指向下一个参数的地址 */ 1. ap += _INTSIZEOF(t); // 当前,ap已经指向下一个参数了 /* ap减去当前参数的大小得到当前参数的地址,再强制类型转换后返回它的值 */ 2. return *(t *)( ap - _INTSIZEOF(t))回想到printf/scanf系列函数的%d %s之类的格式化指令,我们不难理解这些它们的用途了- 明示参数强制转换的类型。(注:printf/scanf没有使用va_xxx来实现,但原理是一致的。)3.va_end很简单,仅仅是把指针作废而已。#define va_end(ap) (ap = (va_list)0) // x86平台五、简洁、灵活,也有风险从va的实现可以看出,指针的合理运用,把C语言简洁、灵活的特性表现得淋漓尽致,叫人不得不佩服C的强大和高效。不可否认的是,给编程人员太多自由空间必然使程序的安全性降低。va中,为了得到所有传递给函数的参数,需要用va_arg依次遍历。其中存在两个隐患:1)如何确定参数的类型。 va_arg在类型检查方面与其说非常灵活,不如说是很不负责,因为是强制类型转换,va_arg都把当前指针所指向的内容强制转换到指定类型;2)结束标志。如果没有结束标志的判断,va将按默认类型依次返回内存中的内容,直到访问到非法内存而出错退出。例2中SqSum()求的是自然数的平方和,所以我把负数和0作为它的结束标志。例如scanf把接收到的回车符作为结束标志,大家熟知的printf()对字符串的处理用'\0'作为结束标志,无法想象C中的字符串如果没有'\0', 代码将会是怎样一番情景,估计那时最流行的可能是字符数组,或者是malloc/free。允许对内存的随意访问,会留给不怀好意者留下攻击的可能。当处理cracker精心设计好的一串字符串后,程序将跳转到一些恶意代码区域执行,以使cracker达到其攻击目的。(常见的exploit攻击)所以,必需禁止对内存的随意访问和严格控制内存访问边界。六、Unix System V兼容方式的va声明上面介绍可变参数函数的声明是采用ANSI标准的,Unix System V兼容方式的声明有一点点区别,它增加了两个宏:va_alist,va_dcl。而且它们不是定义在stdarg.h中,而是varargs.h中。stdarg.h是ANSI标准的;varargs.h仅仅是为了能与以前的程序保持兼容而出现的,现在的编程中不推荐使用。va_alist:函数声明/定义时出现在函数头,用以接受参数列表。va_dcl:对va_alist的声明,其后无需跟分号";"va_start的定义也不相同。因为System V可变参数函数声明不区分固定参数和可选参数,直接对参数列表操作。所以va_start()不是va_start(ap,v),而是简化为va_start(ap)。其中,ap是va_list型的参数指针。Unix System V兼容方式下函数的声明形式:type VAFunction(va_alist) va_dcl // 这里无需分号 { // 函数体内同ANSI标准 }例3:猜测execl的实现(Unix System V兼容方式),摘自SUS V2#include <varargs.h> #define MAXARGS 100 / * execl(file, arg1, arg2, ..., (char *)0); */ execl(va_alist) va_dcl { va_list ap; char *file; char *args[MAXARGS]; int argno = 0; va_start(ap); file = va_arg(ap, char *); while ((args[argno++] = va_arg(ap, char *)) != (char *)0) ; va_end(ap); return execv(file, args); }七、扩展与思考个数可变参数在声明时只需"..."即可;但是,我们在接受这些参数时不能"..."。va函数实现的关键就是如何得到参数列表中可选参数,包括参数的值和类型。以上的所有实现都是基于来自stdarg.h的va_xxx的宏定义。 <思考>能不能不借助于va_xxx,自己实现VA呢?,我想到的方法是汇编。在C中,我们当然就用C的嵌入汇编来实现,这应该是可以做得到的。至于能做到什么程度,稳定性和效率怎么样,主要要看你对内存和指针的控制了。八、写一个简单的可变参数的C函数下面我们来探讨如何写一个简单的可变参数的C函数.写可变参数的 C函数要在程序中用到以下这些宏:void va_start( va_list arg_ptr, prev_param ); type va_arg( va_list arg_ptr, type ); void va_end( va_list arg_ptr ); va在这里是variable-argument(可变参数)的意思. 这些宏定义在stdarg.h中,所以用到可变参数的程序应该包含这个 头文件.下面我们写一个简单的可变参数的函数,改函数至少有一个整数 参数,第二个参数也是整数,是可选的.函数只是打印这两个参数的值.void simple_va_fun(int i, ...) { va_list arg_ptr; int j=0; va_start(arg_ptr, i); j=va_arg(arg_ptr, int); va_end(arg_ptr); printf("%d %d\n", i, j); return; } 我们可以在我们的头文件中这样声明我们的函数: extern void simple_va_fun(int i, ...); 我们在程序中可以这样调用: simple_va_fun(100); simple_va_fun(100,200); 从这个函数的实现可以看到,我们使用可变参数应该有以下步骤: 1)首先在函数里定义一个va_list型的变量,这里是arg_ptr,这个变 量是指向参数的指针. 2)然后用va_start宏初始化变量arg_ptr,这个宏的第二个参数是第 一个可变参数的前一个参数,是一个固定的参数. 3)然后用va_arg返回可变的参数,并赋值给整数j. va_arg的第二个 参数是你要返回的参数的类型,这里是int型. 4)最后用va_end宏结束可变参数的获取.然后你就可以在函数里使 用第二个参数了.如果函数有多个可变参数的,依次调用va_arg获 取各个参数. 如果我们用下面三种方法调用的话,都是合法的,但结果却不一样: 1)simple_va_fun(100); 结果是:100 -123456789(会变的值) 2)simple_va_fun(100,200); 结果是:100 200 3)simple_va_fun(100,200,300); 结果是:100 200 我们看到第一种调用有错误,第二种调用正确,第三种调用尽管结果 正确,但和我们函数最初的设计有冲突.下面一节我们探讨出现这些结果 的原因和可变参数在编译器中是如何处理的. (二)可变参数在编译器中的处理 我们知道va_start,va_arg,va_end是在stdarg.h中被定义成宏的, 由于1)硬件平台的不同 2)编译器的不同,所以定义的宏也有所不同,下 面以VC++中stdarg.h里x86平台的宏定义摘录如下(’\’号表示折行):typedef char * va_list; #define _INTSIZEOF(n) \ ((sizeof(n)+sizeof(int)-1)&~(sizeof(int) - 1) ) #define va_start(ap,v) ( ap = (va_list)&v + _INTSIZEOF(v) ) #define va_arg(ap,t) \ ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) ) #define va_end(ap) ( ap = (va_list)0 ) 定义_INTSIZEOF(n)主要是为了某些需要内存的对齐的系统.C语言的函 数是从右向左压入堆栈的,图(1)是函数的参数在堆栈中的分布位置.我 们看到va_list被定义成char,有一些平台或操作系统定义为void.再 看va_start的定义,定义为&v+_INTSIZEOF(v),而&v是固定参数在堆栈的 地址,所以我们运行va_start(ap, v)以后,ap指向第一个可变参数在堆 栈的地址,如图: 高地址|-----------------------------| |函数返回地址 | |-----------------------------| |....... | |-----------------------------| |第n个参数(第一个可变参数) | |-----------------------------|<--va_start后ap指向 |第n-1个参数(最后一个固定参数)| 低地址|-----------------------------|<-- &v 图( 1 ) 然后,我们用va_arg()取得类型t的可变参数值,以上例为int型为例,我 们看一下va_arg取int型的返回值: j= ( *(int*)((ap += \_INTSIZEOF(int))-\_INTSIZEOF(int)) ); 首先ap+=sizeof(int),已经指向下一个参数的地址了.然后返回 ap-sizeof(int)的int*指针,这正是第一个可变参数在堆栈里的地址 (图2).然后用*取得这个地址的内容(参数值)赋给j. 高地址|-----------------------------| |函数返回地址 | |-----------------------------| |....... | |-----------------------------|<--va_arg后ap指向 |第n个参数(第一个可变参数) | |-----------------------------|<--va_start后ap指向 |第n-1个参数(最后一个固定参数)| 低地址|-----------------------------|<-- &v 图( 2 )最后要说的是va_end宏的意思,x86平台定义为ap=(char*)0;使ap不再 指向堆栈,而是跟NULL一样.有些直接定义为((void*)0),这样编译器不 会为va_end产生代码,例如gcc在linux的x86平台就是这样定义的. 在这里大家要注意一个问题:由于参数的地址用于va_start宏,所 以参数不能声明为寄存器变量或作为函数或数组类型. 关于va_start, va_arg, va_end的描述就是这些了,我们要注意的 是不同的操作系统和硬件平台的定义有些不同,但原理却是相似的. (三)可变参数在编程中要注意的问题 因为va_start, va_arg, va_end等定义成宏,所以它显得很愚蠢, 可变参数的类型和个数完全在该函数中由程序代码控制,它并不能智能 地识别不同参数的个数和类型. 有人会问:那么printf中不是实现了智能识别参数吗?那是因为函数 printf是从固定参数format字符串来分析出参数的类型,再调用va_arg 的来获取可变参数的.也就是说,你想实现智能识别可变参数的话是要通 过在自己的程序里作判断来实现的. 另外有一个问题,因为编译器对可变参数的函数的原型检查不够严 格,对编程查错不利.如果simple_va_fun()改为:void simple_va_fun(int i, ...) { va_list arg_ptr; char *s=NULL; va_start(arg_ptr, i); s=va_arg(arg_ptr, char*); va_end(arg_ptr); printf("%d %s\n", i, s); return; } 可变参数为char*型,当我们忘记用两个参数来调用该函数时,就会出现 core dump(Unix) 或者页面非法的错误(window平台).但也有可能不出 错,但错误却是难以发现,不利于我们写出高质量的程序. 以下提一下va系列宏的兼容性. System V Unix把va_start定义为只有一个参数的宏: va_start(va_list arg_ptr); 而ANSI C则定义为: va_start(va_list arg_ptr, prev_param); 如果我们要用system V的定义,应该用vararg.h头文件中所定义的 宏,ANSI C的宏跟system V的宏是不兼容的,我们一般都用ANSI C,所以 用ANSI C的定义就够了,也便于程序的移植.
-
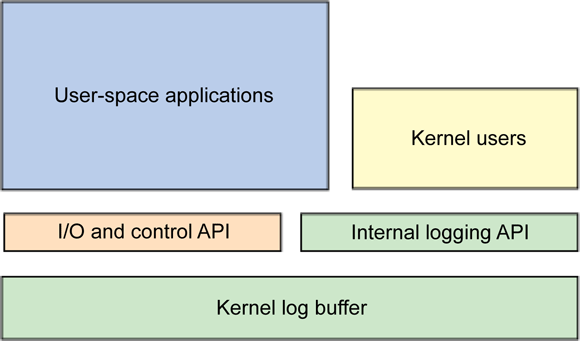
内核日志:API及实现 [TOC]内核版本:Linux5.4.0本文首先通过介绍用于配置和收集日志信息的应用程序接口(API)来说明了内核的日志(见图 1 关于总结框架和组件的示意图)。然后,本文介绍了日志数据从内核到用户空间的移动过程。最后,本文还介绍了基于内核的日志数据的目标:用户空间中使用 rsyslog 进行日志管理。内核API内核的日志是通过 printk 函数实现的,它与用户空间对应函数 printf(按格式打印)具有相似的作用。printf 命令在编程语言中已存在很长时间,最近出现是在 C 语言中,但是最早出现可以追溯到 50 年代和 60 年代的 Fortran(PRINT 和 FORMAT 语句)、BCPL(writf 函数;BCPL 是 C 的前身)和 ALGOL 68 语言(printf 和 putf)。在内核中,printk(打印内核)可以使用与 printf 函数几乎一样的格式将将格式化消息写入到缓冲区。您可以在 ./linux/include/linux/kernel.h(及其实现 ./linux/kernel/printk.c)中看到 printk 的格式:int printk( const char * fmt, ... );这个格式表示的是一个用于定义文本和格式的字符串(类似于 printf),它同时带有一组可变个数参数(由省略号表示 [...])。内核配置与错误通过 printk 实现的日志是通过内核配置选项 CONFIG_PRINTK 激活的。虽然 CONFIG_PRINTK 一般都是激活的,但是不包含这个选项的系统对内核的调用会返回一个 ENOSYS 错误返回值。在使用 printk 时,您首先会发现的不同点更多是关于协议,而不是功能的。这个特性使用了 C 语言的一种模糊方面来简化消息级别和优先级的规范。内核允许每一个消息根据日志级别(定义不同消息重要必的八种级别之一)来分类。这些级别可以用来判断系统是否不可用(紧急消息)、是否发现严重状况(严重消息)或者是否为简单报告消息。 这个内核代码直接将日志级别定义消息的第一个参数,下面这个例子说明的就是严重消息的定义:printk( KERN_CRIT "Error code %08x.\n", val );注意,第一个参数并不一个真正的参数,因为其中没有用于分隔级别(KERN_CRIT)和格式字符的逗号(,)。KERN_CRIT 本身只是一个普通的字符串(事实上,它表示的是字符串 "2";表 1 列出了完整的日志级别清单)。作为预处理程序的一部分,C 会自动地使用一个名为 字符串串联 的功能将这两个字符串组合在一起。组合的结果是将日志级别和用户指定的格式字符串包含在一个字符串中。注意,如果调用者未将日志级别提供给 printk,那么系统就会使用默认值 KERN_WARNING(表示只有 KERN_WARNING 级别以上的日志消息会被记录。)在头文件include/linux/kernel_levels.h里面,定义了日志级别和使用方法:// 位置:include/linux/kernel_levels.h #define KERN_SOH "\001" /* ASCII Start Of Header */ #define KERN_SOH_ASCII '\001' #define KERN_EMERG KERN_SOH "0" /* system is unusable */ #define KERN_ALERT KERN_SOH "1" /* action must be taken immediately */ #define KERN_CRIT KERN_SOH "2" /* critical conditions */ #define KERN_ERR KERN_SOH "3" /* error conditions */ #define KERN_WARNING KERN_SOH "4" /* warning conditions */ #define KERN_NOTICE KERN_SOH "5" /* normal but significant condition */ #define KERN_INFO KERN_SOH "6" /* informational */ #define KERN_DEBUG KERN_SOH "7" /* debug-level messages */ #define KERN_DEFAULT KERN_SOH "d" /* the default kernel loglevel */printk可以在内核的任意上下文中调用。这个调用从 ./linux/kernel/printk.c 中的 printk 函数开始,它会在使用 va_start 解析可变长度参数之后调用 vprintk(在同一个源文件)。printk函数的实现如下:asmlinkage __visible int printk(const char *fmt, ...) { va_list args; // 可变参数 int r; va_start(args, fmt); r = vprintk_func(fmt, args); va_end(args); return r; } EXPORT_SYMBOL(printk);其中vprintk_func()函数定以如下:__printf(1, 0) int vprintk_func(const char *fmt, va_list args) { /* * Try to use the main logbuf even in NMI. But avoid calling console * drivers that might have their own locks. */ if ((this_cpu_read(printk_context) & PRINTK_NMI_DIRECT_CONTEXT_MASK) && raw_spin_trylock(&logbuf_lock)) { int len; len = vprintk_store(0, LOGLEVEL_DEFAULT, NULL, 0, fmt, args); raw_spin_unlock(&logbuf_lock); defer_console_output(); return len; } /* Use extra buffer in NMI when logbuf_lock is taken or in safe mode. */ if (this_cpu_read(printk_context) & PRINTK_NMI_CONTEXT_MASK) return vprintk_nmi(fmt, args); /* Use extra buffer to prevent a recursion deadlock in safe mode. */ if (this_cpu_read(printk_context) & PRINTK_SAFE_CONTEXT_MASK) return vprintk_safe(fmt, args); /* No obstacles. */ return vprintk_default(fmt, args); }vprintk 函数执行了许多管理级检查(递归检查),然后获取日志缓冲区的锁(\_\_log_buf)。接下来,它会对输入的字符串进行日志级别检查; 如果发现日志级别信息,那么对应的日志级别就会被设置。最后,vprintk 会获取当前时间(使用函数 cpu_clock)并使用 sprintf(不是标准库版本,而是在 ./linux/lib/vsprintf.c 中实现的内部内核版本)将它转换成一个字符串。这个字符串会被传递给 printk,然后它会被一个管理缓冲边界(emit_log_char)的特殊函数复制到内核日志缓冲区中。这个函数最后将获取和释放执行控制台信号,并将下一条日志消息发送到控制台(在 release_console_sem 中执行)。内核缓冲缓冲区的大小初始值为 4KB,但是最新的内核大小已经升级到 16KB(在不同的体系架构上,这个值最高可以达到 1MB)。日志辅助函数内核也提供了一些日志辅助函数,它们可以简化日志函数的使用。每一个日志级别都有一个对应的函数,它会扩展为 printk 函数的一个宏。例如,如果要使用 printk 处理 KERN_EMERG 日志级别时,您可以直接使用 pr_emerg。所有宏都已列在 ./linux/include/linux/kernel.h 文件中。至此,您已经了解用于将日志消息插入到内核环缓冲区的 API。现在,让我们讨论一下用于将数据从内核移动到用户空间的方法。内核日志与接口多用途的 syslog 系统调用提供了内核的日志缓冲区访问方法。这个调用执行了很多个操作,所有操作都可以在用户空间执行,但是只有一个操作可以被非 root 用户执行。syslog 系统调用的原型定义位于 ./linux/include/linux/syslog.h;而它的实现位于 ./linux/kernel/printk.c。syslog 调用是作为内核日志消息环缓冲区的输入/输出(I/O)和控制接口。通过 syslog 调用,应用程序可以读取日志消息(部分、整体或者只读取新消息), 以及控制环缓冲区的行为(清除内容、设置日志的消息级别、启用或禁用控制台等等)。图 2 用图形说明了使用所讨论的主要组件进行日志记录的过程。syslog 调用(在内核中调用 ./linux/kernel/printk.c 的 do_syslog)是一个相对较小的函数,它能够读取和控制内核环缓冲区。注意在 glibc 2.0 中,由于词汇 syslog 使用过于广泛,这个函数的名称被修改成 klogctl,它指的是各种调用和应用程序。syslog 和 klogctl(在用户空间中)的原型函数定义为:int syslog( int type, char *bufp, int len ); int klogctl( int type, char *bufp, int len );type 参数是用于传递所执行的命令,它指定了可选的缓冲区长度。有一些命令(如清除环缓冲)是忽略 bufp 和 len 这两个参数的。虽然前面两个命令类型不会对内核进行任何操作,但是其余命令则是用于读取日志消息或控制日志。其中有三个命令是用于读取日志消息的。SYSLOG_ACTION_READ 用于阻塞操作,直至日志消息到达后才释放该操作,然后将它们返回到所提供的缓冲区。这个命令会处理这些消息(旧的消息将不会出现在这个命令的后续调用中。)SYSLOG_ACTION_READ_ALL 命令会从日志读取最后 n 个字符(而 n 是在传递给 klogctl 的参数 'len' 中定义的)。SYSLOG_ACTION_READ_CLEAR 命令会先执行 SYSLOG_ACTION_READ_ALL 操作,然后执行 SYSLOG_ACTION_CLEAR 命令(清除环缓冲区)。SYSLOG_ACTION_CONSOLE ON 和 OFF 可以将日志级别设置为激活或禁用日志消息输出到控制台,而 SYSLOG_CONSOLE_LEVEL 则允许调用者定义控制台所接受的日志消息级别。最后,SYSLOG_ACTION_SIZE_BUFFER 是用于返回内核环缓冲区大小,而 SYSLOG_ACTION_SIZE_UNREAD 则返回当前内核环缓冲区可读取的字符数。表 2 显示了 SYSLOG 命令的完整清单。使用 syslog/klogctl 系统调用实现的命令:#ifndef _LINUX_SYSLOG_H #define _LINUX_SYSLOG_H /* Close the log. Currently a NOP. */ #define SYSLOG_ACTION_CLOSE 0 /* Open the log. Currently a NOP. */ #define SYSLOG_ACTION_OPEN 1 /* Read from the log. */ #define SYSLOG_ACTION_READ 2 /* Read all messages remaining in the ring buffer. */ #define SYSLOG_ACTION_READ_ALL 3 /* Read and clear all messages remaining in the ring buffer */ #define SYSLOG_ACTION_READ_CLEAR 4 /* Clear ring buffer. */ #define SYSLOG_ACTION_CLEAR 5 /* Disable printk's to console */ #define SYSLOG_ACTION_CONSOLE_OFF 6 /* Enable printk's to console */ #define SYSLOG_ACTION_CONSOLE_ON 7 /* Set level of messages printed to console */ #define SYSLOG_ACTION_CONSOLE_LEVEL 8 /* Return number of unread characters in the log buffer */ #define SYSLOG_ACTION_SIZE_UNREAD 9 /* Return size of the log buffer */ #define SYSLOG_ACTION_SIZE_BUFFER 10 #define SYSLOG_FROM_READER 0 #define SYSLOG_FROM_PROC 1 int do_syslog(int type, char __user *buf, int count, int source); #endif /* _LINUX_SYSLOG_H */在实现上面的 syslog/klogctl 层之后,kmsg proc 文件系统成为一个 I/O 通道(在 ./linux/fs/proc/kmsg.c 中实现的),它提供了从内核缓冲区读取日志消息的二进制接口。这个读取操作通常是由一个守护程序(klogd 或 rsyslogd)实现的,它会处理这些消息,然后将它们传递给 rsyslog,以便(基于它的配置)转发到正确的日志文件中。文件 /proc/kmsg 实现了少数等同于内部 do_syslog 的文件操作。在内部,open 调用与 SYSLOG_ACTION_OPEN 有关,而 SYSLOG_ACTION_CLOSE 则与 release 有关(每一个调用都实现为一个 No Operation Performed [NOP])。这个轮循操作会等待文件活动的完成,然后才调用 SYSLOG_ACTION_SIZE_UNREAD 确定可以读取的字符数。最后,read 操作会被映射到 SYSLOG_ACTION_READ,以处理可用的日志消息。注意,用户是不会用到 /proc/kmsg 文件的:守护程序用它来获取日志消息,并将它们转发到 /var 空间内必要的日志文件中。用户空间应用程序用户空间提供了许多读取和管理内核日志的访问方法。我们开始先介绍较底层的接口(如 /proc 文件系统配置元素),然后再介绍更高层的应用程序。/proc 文件系统不仅提供了一个访问日志消息(kmsg)的二进制接口。它还有许多与上面讨论的 syslog/klogctl 相关或无关的配置元素。清单 1 显示了这些参数。清单 1. /proc 中的 printk 配置参数mtj@ubuntu:~$ cat /proc/sys/kernel/printk 4 4 1 7 mtj@ubuntu:~$ cat /proc/sys/kernel/printk_delay 0 mtj@ubuntu:~$ cat /proc/sys/kernel/printk_ratelimit 5 mtj@ubuntu:~$ cat /proc/sys/kernel/printk_ratelimit_burst 10在清单 1 中,第一项定义了 printk API 当前使用的日志级别。这些日志级别表示了控制台的日志级别、默认消息日志级别、最小控制台日志级别和默认控制台日志级别。printk_delay 值表示的是 printk 消息之间的延迟毫秒数(用于提高某些场景的可读性)。注意,这里它的值为 0,而它是不可以通过 /proc 设置的。printk_ratelimit 定义了消息之间允许的最小时间间隔(当前定义为每 5 秒内的某个内核消息数)。消息数量是由 printk_ratelimit_burst 定义的(当前定义为 10)。如果您拥有一个非正式内核而又使用有带宽限制的控制台设备(如通过串口), 那么这非常有用。注意,在内核中,速度限制是由调用者控制的,而不是在 printk 中实现的。如果一个 printk 用户要求进行速度限制,那么该用户就需要调用 printk_ratelimit 函数。dmesg 命令也可用于打印和控制内核环缓冲区。这个命令使用 klogctl 系统调用来读取内核环缓冲区,并将它转发到标准输出(stdout)。这个命令也可以用来清除内核环缓冲区(使用 -c 选项),设置控制台日志级别(-n 选项),以及定义用于读取内核日志消息的缓冲区大小(-s 选项)。注意,如果没有指定缓冲区大小,那么 dmesg 会使用 klogctl 的 SYSLOG_ACTION_SIZE_BUFFER 操作确定缓冲区大小。最后,所有日志应用程序都是基于一个标准化日志框架 syslog,主流操作系统(包括 Linux® 和 Berkeley Software Distribution [BSD])都实现了这个框架。syslog 使用自身的协议实现在不同传输协议的事件通知消息传输(将组件分成发起者、中继者和收集者)。在许多情况中,所有这三种组件都在一个主机上实现。除了 syslog 的许多有意思的特性,它还规定了日志信息是如何收集、过滤和存储的。syslog 已经经过了许多的变化和发展。您可能听过 syslog、klog 或 sysklogd。最新版本的 Ubuntu 使用的是名为 rsyslog(基于原先的 syslog)的新版本 syslog,它指的是可靠的和扩展的 syslogd。syslogd 守护程序通过它的配置文件 /etc/rsyslog.conf 来理解 /proc 文件系统的 kmsg 接口,并使用这些接口获取内核日志消息。注意,在内部,所有日志级别都是通过 /proc/kmsg 写入的,这样所传输的日志级别就不是由内核决定的,而是由 rsyslog 本身决定的。然后这些内核日志消息会存储在 /var/log/kern.log(及其他配置的文件)。在 /var/log 中有许多的日志文件,包括一般消息和系统相调用(/var/log/messages)、系统启动日志(/var/log/boot.log)、认证日志(/var/log/auth.log)等等。虽然您可以检查这些日志,但是您也可以使用它们进行自动审计和检查。有许多日志文件分析器可以用于故障修复, 或者满足安全规范要求,以及自动地使用诸如模式识别或相关性分析(甚至是跨系统的)来发现问题。结束语本文简单地介绍了内核日志和一些应用程序—包括在内核中创建内核日志消息,在内核的环缓冲区存储消息,使用 syslog/klogctl 或 /proc/kmsg 实现到用户空间的消息传输,通过 rsyslog 日志框架实现转发,以及它在 /var/log 子树的最终测试位置。Linux 提供了(包括内核及外部空间的)丰富且灵活的日志框架。
-
在qemu上运行ARM 代码仓库在https://github.com/ADTXL/qemu_kernel喜欢的话可以点下star1. 简介学习kenel,使用qemu搭建环境2. 使用说明2.1 编译安装qemu参考qemu/readme.md2.2 安装toolchain本来打算把toolchain也直接上传的,arm64的toolchain有些文件大于100M,不太好直接上传,只上传了arm32的toolchain.如果对版本没有要求可以直接使用命令安装,# 32 bit sudo apt-get install gcc-arm-linux-gnueabihf # 64 bit sudo apt install gcc-aarch64-linux-gnu2.3 编译以编译和运行arm64为例2.3.1 修改路径运行脚本时需要修改脚本run_qemu中和路径"qemuBinPath"和"KernelRootPath"为真实的存在路径2.3.2 编译有些包没有的可能需要安装下,还有些缺少的根据编译报错安装即可,下面是我编译时需要的包sudo apt install bison sudo apt install flex sudo apt install openssl sudo apt install libssl-dev sudo apt install bc然后编译cd buildroot/linux/qemu/arm make -j62.3.3 运行使用如下命令cd buildroot/linux/qemu/arm ./run_qemu.sh如下所示:user@b10fa2dc8f66:~/txl/project/qemu_kernel/buildroot/linux/qemu/arm$ ./run_qemu.sh run qemu without external filesystem mke2fs 1.44.1 (24-Mar-2018) Creating regular file /home/user/txl/project/qemu_kernel/work/linux-qemu-arm-4_19/image/rootfs.ext4 Creating filesystem with 512000 1k blocks and 128016 inodes Filesystem UUID: 61e2e1d6-dbfb-4068-a749-eba9e5bbfe54 Superblock backups stored on blocks: 8193, 24577, 40961, 57345, 73729, 204801, 221185, 401409 Allocating group tables: done Writing inode tables: done Creating journal (8192 blocks): done Copying files into the device: done Writing superblocks and filesystem accounting information: ...... [ 0.794850] devtmpfs: mounted [ 0.969362] Freeing unused kernel memory: 768K [ 0.971016] Run /sbin/init as init process mount: mounting tmpfs on /tmp failed: Invalid argument mount: mounting sdcardfs on /sdcard failed: No such device [ 1.102253] EXT4-fs (vda): re-mounted. Opts: (null) Processing /etc/profile... Done / # ls bin home lost+found root sys usr dev lib mnt sbin system var etc linuxrc proc sdcard tmp 如果想退出,按Ctrl +a,然后再按x即可。3. 目录结构说明TODO