搜索到
126
篇与
的结果
-
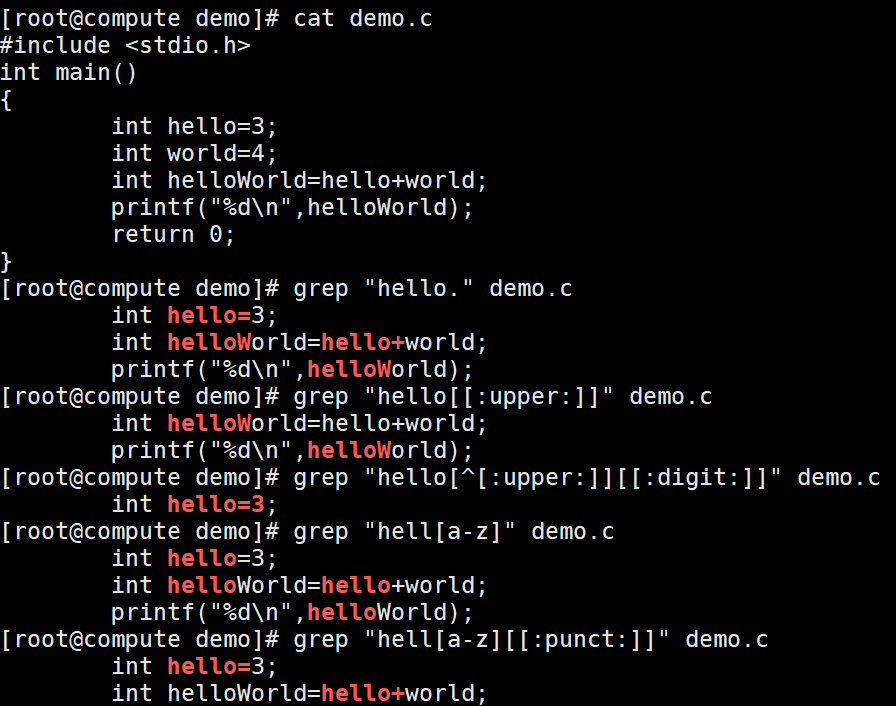
 Linux grep命令 Linux grep命令简介Linux grep 命令用于查找文件里符合条件的字符串。grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。grep家族总共有三个:grep,egrep,fgrep。语法grep [选项] "模式" [文件] grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示行数>][-C<显示行数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...] 参数-a 或 --text : 不要忽略二进制的数据。-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。-c 或 --count : 计算符合样式的列数。-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。-d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。-e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。-E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。-f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。-F 或 --fixed-regexp : 将样式视为固定字符串的列表。-G 或 --basic-regexp : 将样式视为普通的表示法来使用。-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。-i 或 --ignore-case : 忽略字符大小写的差别。-l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。-o 或 --only-matching : 只显示匹配PATTERN 部分。-q 或 --quiet或--silent : 不显示任何信息。-r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。-s 或 --no-messages : 不显示错误信息。-v 或 --invert-match : 显示不包含匹配文本的所有行。-V 或 --version : 显示版本信息。-w 或 --word-regexp : 只显示全字符合的列。比如找like,就不会匹配文本中的liker-x --line-regexp : 只显示全列符合的列。-y : 此参数的效果和指定"-i"参数相同。模式部分直接输入要匹配的字符串,这个可以用fgrep(fast grep)代替来提高查找速度,比如我要匹配一下hello.c文件中printf的个数:fgrep -c "printf" hello.c使用基本正则表达式,下面谈关于基本正则表达式的使用:匹配字符: . :任意一个字符。[abc] :表示匹配一个字符,这个字符必须是abc中的一个。[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。1 :匹配一个字符,这个字符是除了1、2、3以外的所有字符。对于一些常用的字符集,系统做了定义:[A-Za-z] 等价于 [[:alpha:]][0-9] 等价于 [[:digit:]][A-Za-z0-9] 等价于 [[:alnum:]]tab,space 等空白字符 [[:space:]][A-Z] 等价于 [[:upper:]][a-z] 等价于 [[:lower:]]标点符号 [[:punct:]]匹配次数:{m,n} :匹配其前面出现的字符至少m次,至多n次。? :匹配其前面出现的内容0次或1次,等价于{0,1}。:匹配其前面出现的内容任意次,等价于{0,},所以 ".*" 表述任意字符任意次,即无论什么内容全部匹配。位置锚定:^ :锚定行首$ :锚定行尾。技巧" ^$ "用于匹配空白行。\b或\<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker\b或\>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like\B :与\b作用相反。分组及引用:(string) :将string作为一个整体方便后面引用\1 :引用第1个左括号及其对应的右括号所匹配的内容。\2 :引用第2个左括号及其对应的右括号所匹配的内容。\n :引用第n个左括号及其对应的右括号所匹配的内容。扩展的(Extend)正则表达式注意:使用扩展的正则表达式要加-E选项,或者世界使用egrep匹配字符: 与基本正则表达式一样匹配次数::和基本正则表达式一样? :基本正则表达式是?,这里没有\。{m,n} :相比基本正则表达式也是没有了\。:匹配其前面的字符至少一次,相当于{1,}。位置锚定:和基本正则表达式一样。分组及引用:(string) :相比基本正则表达式也是没有了\。\1 :引用部分和基本正则表达式一样。\n :引用部分和基本正则表达式一样。或者:a|b :匹配a或b,注意a是指 | 的左边的整体,b也同理。比如 C|cat 表示的是 C或cat,而不是Cat或cat,如果要表示Cat或cat,则应该写为 (C|c)at 。记住(string)除了用于引用还用于分组。注1:默认情况下,正则表达式的匹配工作在贪婪模式下,也就是说它会尽可能长地去匹配,比如某一行有字符串 abacb,如果搜索内容为 "a.*b" 那么会直接匹配 abacb这个串,而不会只匹配ab或acb。注2:所有的正则字符,如 [ 、* 、( 等,若要搜索 ,而不是想把 解释为重复先前字符任意次,可以使用 * 来转义。参考:Linux grep命令-菜鸟教程linux中grep命令的用法123 ↩
Linux grep命令 Linux grep命令简介Linux grep 命令用于查找文件里符合条件的字符串。grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。grep家族总共有三个:grep,egrep,fgrep。语法grep [选项] "模式" [文件] grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示行数>][-C<显示行数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...] 参数-a 或 --text : 不要忽略二进制的数据。-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。-c 或 --count : 计算符合样式的列数。-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。-d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。-e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。-E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。-f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。-F 或 --fixed-regexp : 将样式视为固定字符串的列表。-G 或 --basic-regexp : 将样式视为普通的表示法来使用。-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。-i 或 --ignore-case : 忽略字符大小写的差别。-l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。-o 或 --only-matching : 只显示匹配PATTERN 部分。-q 或 --quiet或--silent : 不显示任何信息。-r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。-s 或 --no-messages : 不显示错误信息。-v 或 --invert-match : 显示不包含匹配文本的所有行。-V 或 --version : 显示版本信息。-w 或 --word-regexp : 只显示全字符合的列。比如找like,就不会匹配文本中的liker-x --line-regexp : 只显示全列符合的列。-y : 此参数的效果和指定"-i"参数相同。模式部分直接输入要匹配的字符串,这个可以用fgrep(fast grep)代替来提高查找速度,比如我要匹配一下hello.c文件中printf的个数:fgrep -c "printf" hello.c使用基本正则表达式,下面谈关于基本正则表达式的使用:匹配字符: . :任意一个字符。[abc] :表示匹配一个字符,这个字符必须是abc中的一个。[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。1 :匹配一个字符,这个字符是除了1、2、3以外的所有字符。对于一些常用的字符集,系统做了定义:[A-Za-z] 等价于 [[:alpha:]][0-9] 等价于 [[:digit:]][A-Za-z0-9] 等价于 [[:alnum:]]tab,space 等空白字符 [[:space:]][A-Z] 等价于 [[:upper:]][a-z] 等价于 [[:lower:]]标点符号 [[:punct:]]匹配次数:{m,n} :匹配其前面出现的字符至少m次,至多n次。? :匹配其前面出现的内容0次或1次,等价于{0,1}。:匹配其前面出现的内容任意次,等价于{0,},所以 ".*" 表述任意字符任意次,即无论什么内容全部匹配。位置锚定:^ :锚定行首$ :锚定行尾。技巧" ^$ "用于匹配空白行。\b或\<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker\b或\>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like\B :与\b作用相反。分组及引用:(string) :将string作为一个整体方便后面引用\1 :引用第1个左括号及其对应的右括号所匹配的内容。\2 :引用第2个左括号及其对应的右括号所匹配的内容。\n :引用第n个左括号及其对应的右括号所匹配的内容。扩展的(Extend)正则表达式注意:使用扩展的正则表达式要加-E选项,或者世界使用egrep匹配字符: 与基本正则表达式一样匹配次数::和基本正则表达式一样? :基本正则表达式是?,这里没有\。{m,n} :相比基本正则表达式也是没有了\。:匹配其前面的字符至少一次,相当于{1,}。位置锚定:和基本正则表达式一样。分组及引用:(string) :相比基本正则表达式也是没有了\。\1 :引用部分和基本正则表达式一样。\n :引用部分和基本正则表达式一样。或者:a|b :匹配a或b,注意a是指 | 的左边的整体,b也同理。比如 C|cat 表示的是 C或cat,而不是Cat或cat,如果要表示Cat或cat,则应该写为 (C|c)at 。记住(string)除了用于引用还用于分组。注1:默认情况下,正则表达式的匹配工作在贪婪模式下,也就是说它会尽可能长地去匹配,比如某一行有字符串 abacb,如果搜索内容为 "a.*b" 那么会直接匹配 abacb这个串,而不会只匹配ab或acb。注2:所有的正则字符,如 [ 、* 、( 等,若要搜索 ,而不是想把 解释为重复先前字符任意次,可以使用 * 来转义。参考:Linux grep命令-菜鸟教程linux中grep命令的用法123 ↩ -
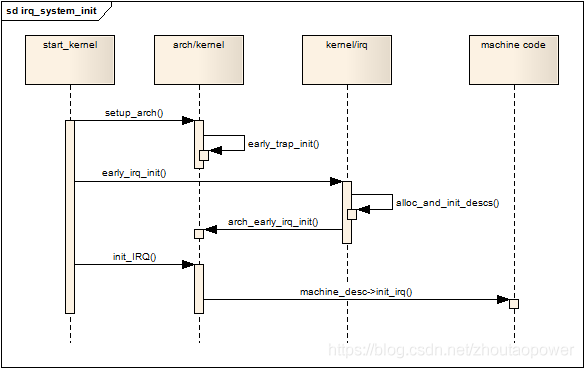
Linux内核中断机制 [TOC]1. 中断的概念中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的 CPU 暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。Linux中通常分为外部中断(又叫硬件中断)和内部中断(又叫异常)。当 CPU 收到一个中断 (IRQ)的时候,会去执行该中断对应的处理函数(ISR)。普通情况下,会有一个中断向量表,向量表中定义了 CPU 对应的每一个外设资源的中断处理程序的入口,当发生对应的中断的时候, CPU 直接跳转到这个入口执行程序。也就是中断上下文。(注意:中断上下文中,不可阻塞睡眠)。2. Linux中断 top/bottom玩过 MCU 的人都知道,中断服务程序的设计最好是快速完成任务并退出,因为此刻系统处于被中断中。但是在 ISR 中又有一些必须完成的事情,比如:清中断标志,读/写数据,寄存器操作等。在 Linux 中,同样也是这个要求,希望尽快的完成 ISR。但事与愿违,有些 ISR 中任务繁重,会消耗很多时间,导致响应速度变差。Linux 中针对这种情况,将中断分为了两部分:上半部(top half):收到一个中断,立即执行,有严格的时间限制,只做一些必要的工作,比如:应答,复位等。这些工作都是在所有中断被禁止的情况下完成的。底半部(bottom half):能够被推迟到后面完成的任务会在底半部进行。在适合的时机,下半部会被开中断执行。3. 中断处理程序驱动程序可以使用接口:request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev)参数含义irq表了该中断的中断号,一般 CPU 的中断号都会事先定义好。handler中断发生后的 ISRflags中断标志( IRQF_DISABLED / IRQFSAMPLE_RANDOM / IRQF_TIMER / IRQF_SHARED)name中断相关的设备 ASCII 文本,例如 "keyboard",这些名字会在 /proc/irq 和 /proc/interrupts 文件使用dev用于共享中断线,传递驱动程序的设备结构。非共享类型的中断,直接设置成为 NULL中断标志flag的含义:标志含义IRQF_DISABLED设置这个标志的话,意味着内核在处理这个 ISR 期间,要禁止其他中断(多数情况不使用这个)IRQFSAMPLE_RANDOM表明这个设备产生的中断对内核熵池有贡献IRQF_TIMER为系统定时器准备的标志IRQF_SHARED表明多个中断处理程序之间共享中断线。同一个给定的线上注册每个处理程序,必须设置这个调用request_irq成功执行返回0。常见错误是 -EBUSY,表示给定的中断线已经在使用(或者没有指定 IRQF_SHARED)注意:request_irq 函数可能引起睡眠,所以不允许在中断上下文或者不允许睡眠的代码中调用。Linux内核熵池:Linux内核采用熵来描述数据的随机性。熵(entropy)是描述系统混乱无序程度的物理量,一个系统的熵越大则说明该系统的有序性越差,即不确定性越大。在信息学中,熵被用来表征一个符号或系统的不确定性,熵越大,表明系统所含有用信息量越少,不确定度越大。计算机本身是可预测的系统,因此,用计算机算法不可能产生真正的随机数。但是机器的环境中充满了各种各样的噪声,如硬件设备发生中断的时间,用户点击鼠标的时间间隔等是完全随机的,事先无法预测。Linux内核实现的随机数产生器正是利用系统中的这些随机噪声来产生高质量随机数序列。核维护了一个熵池用来收集来自设备驱动程序和其它来源的环境噪音。理论上,熵池中的数据是完全随机的,可以实现产生真随机数序列。为跟踪熵池中数据的随机性,内核在将数据加入池的时候将估算数据的随机性,这个过程称作熵估算。熵估算值描述池中包含的随机数位数,其值越大表示池中数据的随机性越好。释放中断:const void *free_irq(unsigned int irq, void *dev_id)用于释放中断处理函数。注意:Linux 中的中断处理程序是无须重入的。当给定的中断处理程序正在执行的时候,其中断线在所有的处理器上都会被屏蔽掉,以防在同一个中断线上又接收到另一个新的中断。通常情况下,除了该中断的其他中断都是打开的,也就是说其他的中断线上的重点都能够被处理,但是当前的中断线总是被禁止的,故,同一个中断处理程序是绝对不会被自己嵌套的。4. 中断上下文与进程上下文不一样,内核执行中断服务程序的时候,处于中断上下文。中断处理程序并没有自己的独立的栈,而是使用了内核栈,其大小一般是有限制的(32bit 机器 8KB)。所以其必须短小精悍。同时中断服务程序是打断了正常的程序流程,这一点上也必须保证快速的执行。同时中断上下文中是不允许睡眠,阻塞的。中断上下文不能睡眠的原因是:1、 中断处理的时候,不应该发生进程切换,因为在中断context中,唯一能打断当前中断handler的只有更高优先级的中断,它不会被进程打断,如果在 中断context中休眠,则没有办法唤醒它,因为所有的wake_up_xxx都是针对某个进程而言的,而在中断context中,没有进程的概念,没 有一个task_struct(这点对于softirq和tasklet一样),因此真的休眠了,比如调用了会导致block的例程,内核几乎肯定会死。2、schedule()在切换进程时,保存当前的进程上下文(CPU寄存器的值、进程的状态以及堆栈中的内容),以便以后恢复此进程运行。中断发生后,内核会先保存当前被中断的进程上下文(在调用中断处理程序后恢复);但在中断处理程序里,CPU寄存器的值肯定已经变化了吧(最重要的程序计数器PC、堆栈SP等),如果此时因为睡眠或阻塞操作调用了schedule(),则保存的进程上下文就不是当前的进程context了.所以不可以在中断处理程序中调用schedule()。3、内核中schedule()函数本身在进来的时候判断是否处于中断上下文:if(unlikely(in_interrupt()))BUG();因此,强行调用schedule()的结果就是内核BUG。4、中断handler会使用被中断的进程内核堆栈,但不会对它有任何影响,因为handler使用完后会完全清除它使用的那部分堆栈,恢复被中断前的原貌。5、处于中断context时候,内核是不可抢占的。因此,如果休眠,则内核一定挂起。5. 举例比如 RTC 驱动程序 (drivers/char/rtc.c)。在 RTC 驱动的初始化阶段,会调用到 rtc_init 函数:module_init(rtc_init);在这个初始化函数中调用到了 request_irq 用于申请中断资源,并注册服务程序:static int __init rtc_init(void) { ... rtc_int_handler_ptr = rtc_interrupt; ... request_irq(RTC_IRQ, rtc_int_handler_ptr, 0, "rtc", NULL) ... }RTC_IRQ 是中断号,和处理器绑定。rtc_interrupt 是中断处理程序:static irqreturn_t rtc_interrupt(int irq, void *dev_id) { /* * Can be an alarm interrupt, update complete interrupt, * or a periodic interrupt. We store the status in the * low byte and the number of interrupts received since * the last read in the remainder of rtc_irq_data. */ spin_lock(&rtc_lock); rtc_irq_data += 0x100; rtc_irq_data &= ~0xff; if (is_hpet_enabled()) { /* * In this case it is HPET RTC interrupt handler * calling us, with the interrupt information * passed as arg1, instead of irq. */ rtc_irq_data |= (unsigned long)irq & 0xF0; } else { rtc_irq_data |= (CMOS_READ(RTC_INTR_FLAGS) & 0xF0); } if (rtc_status & RTC_TIMER_ON) mod_timer(&rtc_irq_timer, jiffies + HZ/rtc_freq + 2*HZ/100); spin_unlock(&rtc_lock); wake_up_interruptible(&rtc_wait); kill_fasync(&rtc_async_queue, SIGIO, POLL_IN); return IRQ_HANDLED; }每次收到 RTC 中断,就会调用进这个函数。6. 中断处理流程发生中断时,CPU执行异常向量vector_irq的代码, 即异常向量表中的中断异常的代码,它是一个跳转指令,跳去执行真正的中断处理程序,在vector_irq里面,最终会调用中断处理的总入口函数。C 语言的入口为 : asm_do_IRQ(unsigned int irq, struct pt_regs *regs)asmlinkage void __exception_irq_entry asm_do_IRQ(unsigned int irq, struct pt_regs *regs) { handle_IRQ(irq, regs); }该函数的入参 irq 为中断号。asm_do_IRQ -> handle_IRQvoid handle_IRQ(unsigned int irq, struct pt_regs *regs) { __handle_domain_irq(NULL, irq, false, regs); }handle_IRQ ->\_\_handle_domain_irqint __handle_domain_irq(struct irq_domain *domain, unsigned int hwirq, bool lookup, struct pt_regs *regs) { struct pt_regs *old_regs = set_irq_regs(regs); unsigned int irq = hwirq; int ret = 0; irq_enter(); #ifdef CONFIG_IRQ_DOMAIN if (lookup) irq = irq_find_mapping(domain, hwirq); #endif /* * Some hardware gives randomly wrong interrupts. Rather * than crashing, do something sensible. */ if (unlikely(!irq || irq >= nr_irqs)) { ack_bad_irq(irq); ret = -EINVAL; } else { generic_handle_irq(irq); } irq_exit(); set_irq_regs(old_regs); return ret; }这里请注意:先调用了 irq_enter 标记进入了硬件中断:irq\_enter是更新一些系统的统计信息,同时在\_\_irq_enter宏中禁止了进程的抢占。虽然在产生IRQ时,ARM会自动把CPSR中的I位置位,禁止新的IRQ请求,直到中断控制转到相应的流控层后才通过local_irq_enable()打开。那为何还要禁止抢占?这是因为要考虑中断嵌套的问题,一旦流控层或驱动程序主动通过local_irq_enable打开了IRQ,而此时该中断还没处理完成,新的irq请求到达,这时代码会再次进入irq\_enter,在本次嵌套中断返回时,内核不希望进行抢占调度,而是要等到最外层的中断处理完成后才做出调度动作,所以才有了禁止抢占这一处理再调用 generic\_handle\_irq最后调用 irq_exit 删除进入硬件中断的标记\_\_handle_domain_irq -> generic_handle_irqint generic_handle_irq(unsigned int irq) { struct irq_desc *desc = irq_to_desc(irq); if (!desc) return -EINVAL; generic_handle_irq_desc(desc); return 0; } EXPORT_SYMBOL_GPL(generic_handle_irq);首先在函数 irq_to_desc 中根据发生中断的中断号,去取出它的 irq_desc 中断描述结构,然后调用 generic_handle_irq_desc:static inline void generic_handle_irq_desc(struct irq_desc *desc) { desc->handle_irq(desc); }这里调用了 handle_irq 函数。所以,在上述流程中,还需要分析 irq_to_desc 流程:struct irq_desc *irq_to_desc(unsigned int irq) { return (irq < NR_IRQS) ? irq_desc + irq : NULL; } EXPORT_SYMBOL(irq_to_desc);NR_IRQS 是支持的总的中断个数,当然,irq 不能够大于这个数目。所以返回 irq_desc + irq。irq_desc 是一个全局的数组:struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = { [0 ... NR_IRQS-1] = { .handle_irq = handle_bad_irq, .depth = 1, .lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock), } };这里是这个数组的初始化的地方。所有的 handle_irq 函数都被初始化成为了 handle_bad_irq。细心的观众可能发现了,调用这个 desc->handle_irq(desc) 函数,并不是咱们注册进去的中断处理函数啊,因为两个函数的原型定义都不一样。这个 handle_irq 是 irq_flow_handler_t 类型,而我们注册进去的服务程序是 irq_handler_t,这两个明显不是同一个东西,所以这里我们还需要继续分析。6.1 中断相关的数据结构Linux中,与中断相关的数据结构有3个结构名称作用irq_descIRQ 的软件层面上的资源描述,用于描述IRQ线的属性与状态,被称为中断描述符。irqactionIRQ 的通用操作irq_chip对应每个芯片的具体实现,用于描述不同类型的中断控制器。irq_chip 是一串和芯片相关的函数指针,这里定义的非常的全面,基本上和 IRQ 相关的可能出现的操作都全部定义进去了,具体根据不同的芯片,需要在不同的芯片的地方去初始化这个结构,然后这个结构会嵌入到通用的 IRQ 处理软件中去使用,使得软件处理逻辑和芯片逻辑完全的分开。6.2 初始化Chip相关的IRQ众所周知,启动的时候,C 语言从 start_kernel 开始,在这里面,调用了和 machine 相关的 IRQ 的初始化 init_IRQ():asmlinkage __visible void __init start_kernel(void) { char *command_line; char *after_dashes; ..... early_irq_init(); init_IRQ(); ..... }在 init_IRQ 中,调用了 machine_desc->init_irq():void __init init_IRQ(void) { int ret; if (IS_ENABLED(CONFIG_OF) && !machine_desc->init_irq) irqchip_init(); else machine_desc->init_irq(); if (IS_ENABLED(CONFIG_OF) && IS_ENABLED(CONFIG_CACHE_L2X0) && (machine_desc->l2c_aux_mask || machine_desc->l2c_aux_val)) { if (!outer_cache.write_sec) outer_cache.write_sec = machine_desc->l2c_write_sec; ret = l2x0_of_init(machine_desc->l2c_aux_val, machine_desc->l2c_aux_mask); if (ret && ret != -ENODEV) pr_err("L2C: failed to init: %d\n", ret); } uniphier_cache_init(); }machine_desc->init_irq() 完成对中断控制器的初始化,为每个irq_desc结构安装合适的流控handler,为每个irq_desc结构安装irq_chip指针,使他指向正确的中断控制器所对应的irq_chip结构的实例,同时,如果该平台中的中断线有多路复用(多个中断公用一个irq中断线)的情况,还应该初始化irq_desc中相应的字段和标志,以便实现中断控制器的级联。这里初始化的时候回调用到具体的芯片相关的中断初始化的地方。int __init s5p_init_irq_eint(void) { int irq; for (irq = IRQ_EINT(0); irq <= IRQ_EINT(15); irq++) irq_set_chip(irq, &s5p_irq_vic_eint); for (irq = IRQ_EINT(16); irq <= IRQ_EINT(31); irq++) { irq_set_chip_and_handler(irq, &s5p_irq_eint, handle_level_irq); set_irq_flags(irq, IRQF_VALID); } irq_set_chained_handler(IRQ_EINT16_31, s5p_irq_demux_eint16_31); return 0; }而在这些里面,都回去调用类似于:void irq_set_chip_and_handler_name(unsigned int irq, struct irq_chip *chip, irq_flow_handler_t handle, const char *name); irq_set_handler(unsigned int irq, irq_flow_handler_t handle) { __irq_set_handler(irq, handle, 0, NULL); } static inline void irq_set_chained_handler(unsigned int irq, irq_flow_handler_t handle) { __irq_set_handler(irq, handle, 1, NULL); } void irq_set_chained_handler_and_data(unsigned int irq, irq_flow_handler_t handle, void *data); 这些函数定义在 include/linux/irq.h 文件。是对芯片初始化的时候可见的 APIs,用于指定中断“流控”中的 :irq_flow_handler_t handle也就是中断来的时候,最后那个函数调用。中断流控函数,分几种,电平触发的中断,边沿触发的等:/* * Built-in IRQ handlers for various IRQ types, * callable via desc->handle_irq() */ extern void handle_level_irq(struct irq_desc *desc); extern void handle_fasteoi_irq(struct irq_desc *desc); extern void handle_edge_irq(struct irq_desc *desc); extern void handle_edge_eoi_irq(struct irq_desc *desc); extern void handle_simple_irq(struct irq_desc *desc); extern void handle_untracked_irq(struct irq_desc *desc); extern void handle_percpu_irq(struct irq_desc *desc); extern void handle_percpu_devid_irq(struct irq_desc *desc); extern void handle_bad_irq(struct irq_desc *desc); extern void handle_nested_irq(unsigned int irq);而在这些处理函数里,会去调用到 : handle_irq_event 比如:/** * handle_level_irq - Level type irq handler * @desc: the interrupt description structure for this irq * * Level type interrupts are active as long as the hardware line has * the active level. This may require to mask the interrupt and unmask * it after the associated handler has acknowledged the device, so the * interrupt line is back to inactive. */ void handle_level_irq(struct irq_desc *desc) { raw_spin_lock(&desc->lock); mask_ack_irq(desc); if (!irq_may_run(desc)) goto out_unlock; desc->istate &= ~(IRQS_REPLAY | IRQS_WAITING); /* * If its disabled or no action available * keep it masked and get out of here */ if (unlikely(!desc->action || irqd_irq_disabled(&desc->irq_data))) { desc->istate |= IRQS_PENDING; goto out_unlock; } kstat_incr_irqs_this_cpu(desc); handle_irq_event(desc); cond_unmask_irq(desc); out_unlock: raw_spin_unlock(&desc->lock); }而这个 handle_irq_event 则是调用了处理,handle_irq_event_percpu:irqreturn_t handle_irq_event(struct irq_desc *desc) { irqreturn_t ret; desc->istate &= ~IRQS_PENDING; irqd_set(&desc->irq_data, IRQD_IRQ_INPROGRESS); raw_spin_unlock(&desc->lock); ret = handle_irq_event_percpu(desc); raw_spin_lock(&desc->lock); irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS); return ret; }handle_irq_event_percpu->\_\_handle_irq_event_percpu-> [action->handler()]这里终于看到了调用 的地方了,就是咱们通过 request_irq 注册进去的函数7. /proc/interrupts这个 proc 下放置了对应中断号的中断次数和对应的 dev-name参考:Linux 中断之中断处理浅析
-
线程与对称处理器 1. 进程和线程进程的概念有两个特点,一是资源所有权。一个进程包括一个存放进程映像的虚拟地址空间;二是调度/执行。一个进程沿着通过一个或多个程序的一条执行路径(轨迹)执行。这两个特点是独立的,为了区分这两个特点,分派的单位通常称作线程,而拥有资源所有权的单位称为进程。1.1 多线程在多线程环境中,进程被定义成资源分配的单位和一个被保护的单位,与进程相关联的有:存放进程映像的虚拟地址空间受保护地对处理器、其他进程(用于进程间通信)、文件和I/O资源的访问。在一个进程中,可能有一个或多个线程,每个线程有:线程执行状态(运行、就绪等)在未运行时保存的线程上下文;从某种意义上看,线程可以被看做进程内的一个被独立地操作的程序计数器一个执行栈用于每个线程局部变量的静态存储空间与进程内的其他线程共享的对进程的内存和资源的访问。线程的优点:在一个已有进程中创建一个新线程比创建一个全新进程所需的时间要少许多。研究表明,在UNIX中,线程的创建比进程快10倍终止一个线程比终止一个进程花费的时间少同一个进程内线程间切换比进程间切换花费的时间少线程提高了不同的执行程序间通信的效率。在大多数操作系统中,独立进程间的通信需要内核的介入,以提供保护和通信所需要的机制。但是,由于同一个进程中的线程共享内存和文件,它们无需调用内核就可以互相通信。
-
并发性:互斥与同步 操作系统设计中的核心问题是关于进程和线程的管理。并发是所有问题的基础,也是操作系统设计的基础。并发包括许多设计问题,其中有进程间通信、资源共享与竞争(例如内存、文件、I/O访问)、多个进程活动的同步以及分配给进程的处理器时间等。和并发相关的一些关键术语:原子操作一个或多个指令的序列,对外是不可分的;即没有其他进程可以看到其中间状态或者中断此操作临界区是一段代码,在这段代码中进程将访问共享资源,当另外一个进程已经在这段代码中运行时,这个进程就不能在这段代码中执行。死锁两个或两个以上的进程因其中的每个进程都在等待其他进程做完某些事情而不能继续执行,这样的情形叫做死锁活锁两个或两个以上进程为了响应其他进程中的变化而持续改变自己的状态但不做有用的工作,这样的情形叫做活锁互斥当一个进程在临界区访问共享资源时,其他进程不能进入该临界区访问任何共享资源,这种情形叫做互斥竞争条件多个线程或者进程在读写一个共享数据时,结果依赖于它们执行的相对时间,这种情形叫做竞争饥饿是指一个可运行的进程尽管可能继续执行,但被调度器无限期地忽视,而不能被调度执行的情况1.并发的原理在单处理器系统的情况下,出现问题的原因是中断可能会在进程中任何地方停止指令的执行;在多处理器系统的情况下,不仅同样的条件可以引发问题,而且当两个进程同时执行并且都试图访问同一个全局变量时,也会引发问题。这两类问题的解决方案是相同的:控制对共享资源的访问1.1 竞争条件竞争条件发生在多个进程或线程读写数据时,其最终的结果依赖于多个进程的指令执行顺序。1.2 操作系统关注的问题并发会带来哪些设计和管理问题?操作系统必须能够记住各个活跃的进程操作系统必须为每个进程分配和释放各种资源。操作系统必须保护每个进程的数据和物理资源,避免其他进程的无意干涉一个进程的功能和输出结果必须与执行速度无关。1.3 进程的交互知道程度关系一个进程对其他进程的影响潜在的控制问题进程之间不知道对方的存在竞争1.一个进程的结果与其他进程的活动无关 2.进程的执行时间可能会受影响互斥、死锁(可复用的资源)、饥饿进程间接知道对方的存在(如共享对象)通过共享合作1.一个进程的结果可能依赖于从其他进程获得的信息 2.进程的执行时间可能会受到影响互斥、死锁(可复用的资源)、饥饿、数据一致性进程直接知道对方的存在(它们有可用的通信原语)通过通信合作1.一个进程的结果可能依赖于从其他进程获得的信息2.进程的计时可能会受到影响死锁(可消费的资源)、饥饿2. 信号量现在讨论操作系统和用于提供并发性的程序设计语言机制。基本原理:两个或多个进程可以通过简单的信号进行合作,一个进程可以被迫在某一位置停止,直到它接收到一个特定的信号。任何复杂的合作需求都可以通过适当的信号结构得到满足,为了发信号,需要使用一个被称作信号量的特殊变量。为通过信号量s发送信号,进程可执行原语semSignal(s)(V操作);为通过信号量s接收信号,进程可执行原语semWait(s)(P操作);如果相应的信号仍然没有发送,则进程被挂起,直到发送完为止。为了达到预期的效果,可以把信号量看做是一个具有整数值的变量,在它之上定义三个操作:1)一个信号量可以初始化成非负数2)semWait操作使信号量减1。如果值变成负数,则执行semWait的进程被阻塞。否则进程继续执行。3)semSignal操作使信号量加1。如果值小于或者等于零,则被semWait操作阻塞的进程被解除阻塞。除了这三种操作外,没有任何其他方法可以检查或操作信号量。解释:开始时,信号量的值为零或正数。如果该值为正数,则该值等于发出semWait操作后可立即继续执行的进程的数量。如果该值为零(或者由于初始化,或者由于有等于信号量初值的进程已经等待),则发出semWait操作的下一个进程会被阻塞,此时该信号量的值变为负值。之后,每个后续的semWait操作都会使信号量的负值更大。该负值等于正在等待接触阻塞的进程的数量。在信号量为负值的情形下,每一个semSignal操作都会将等待进程中的一个进程解除阻塞。在信号量为负值的情形下,每一个semSignal操作都会将等待进程中的一个进程解除阻塞。2.1 互斥使用信号量s解决互斥问题的方法。设有n个进程,用数组P(i)表示,所有的进程都需要访问共享资源。每个进程中进入临界区前执行semWait(s),如果s的值为负,则进程被挂起;如果值为1,则s被减为0,进程立即进入临界区;由于s值不再为正,因而其他任何进程都不能进入临界区。/* program mutualexeclusion */ const int n = /* 进程数 */; semaphore s = 1; void P(int i) { while(true){ semWait(s); /* 临界区 */ semSignal(s); /* 其他部分 */ } } void main() { parbegin(P(1), P(2), ..., P(n)); }
-
-
(1)进程内存管理初探 [TOC]随着cpu技术发展,现在大部分移动设备、PC、服务器都已经使用上64bit的CPU,但是关于Linux内核的虚拟内存管理,还停留在历史的用户态与内核态虚拟内存3:1的观念中,导致在解决一些内存问题时存在误解。例如现在主流的移动设备操作系统Android,经常遇到进程使用大量内存导致被lmk杀死,分配不到内存而触发OOM/ANR,或者分配内存慢导致卡顿,内核态使用哪个分配内存的函数更合理等问题,有些涉及物理内存分配,有些涉及虚拟内存分配,如果不熟悉虚拟内存管理的技术知识,可能走很多弯路。本章节结合代码介绍进程虚拟内存布局以及进程的虚拟内存分配释放流程,涉及的代码是android-8.1, 内核版本kernel-4.9,架构是arm64。1. 几种地址的概念1.1 物理地址每片物理内存存储实际地址,例如一个8GB的内存,0x00000000表示第一个byte的地址,而0xFFFFFFFF表示的是最后一个byte的地址;物理地址的值与实际的内存条上的地址一一对应,物理地址的大小与cpu访问物理内存的总线宽度有一定的关系。1.2 线性地址为了保证系统多任务运行的安全性和可靠性(防止一个任务篡改系统或者其他任务的内存),CPU增加段页式内存管理;段基地址+段内偏移构成的地址就是线性地址;如果开启的分页内存管理,线性地址还要通过MMU计算才能转换出物理地址。1.3 逻辑地址每个进程运行时CPU看到的地址就是逻辑地址,实际上也是线性地址中的段内偏移地址,逻辑地址与段基地址可以计算出线性地址。进程在访问虚拟地址空间的任意合法地址时,都要按照逻辑地址->线性地址->物理地址的顺序换算才能找到对应的物理地址;由于段式内存管理存在性能、访问效率的问题,以及Linux要兼容各种CPU,在Linux内核中所有的用户态进程使用的同一个段,且段基地址都是0,如此既可以兼容的传统的段式内存管理,又可以通过页式内存映射更灵活的管理内存。由于同一个段基地址都是0,对每个进程来说,逻辑地址和线性地址是一样的;同时每个进程的PGD是不一样的,从而保证每个进程之间隔离,不同进程同一个虚拟地址映射的物理地址就不一样了。Linux系统采用延迟分配物理内存的策略,用户态进程每次分配内存时分配的都是虚拟内存,表示一段地址空间已经分配出来供进程使用;当进程第一次访问虚拟地址时,才会发现虚拟地址没有对应的物理内存,系统默认会触发缺页异常,从内核物理内存管理系统中分配物理页,建立页表中把虚拟地址映射到物理地址。对于缺页异常处理流程,页表创建/建立/销毁等操作在以后文章中介绍。2. 进程虚拟内存空间分布理论上,64bit地址支持访问的地址空间是[0, 2(64-1)],而实际上现有的应用程序都不会用这么大的地址空间,并且arm64芯片现在也不支持访问这么大的地址空间,arm64架构芯片最大支持访问48bit的地址空间。例如在Android系统中,整个虚拟地址空间分成两部分,如下图所示:其中[0x0001000000000000,0xFFFF000000000000]之间的地址是不规范地址,不能使用;该段内存把整个虚拟地址空间划分为两段,低段内存为进程用户态地址空间,高段内存为内核地址空间。参考代码arch\arm64\include\asm\memory.h):#define VA_BITS (CONFIG_ARM64_VA_BITS) #define VA_START (UL(0xffffffffffffffff)) << VA_BITS) #define PAGE_OFFSET (UL(0xffffffffffffffff)) << (VA_BITS - 1 )) 如果内核打开CONFIG_COMPAT选项,说明用户态既支持64位进程,也支持32位进程;由于32bit的地址最多可以访问的虚拟地址空间最多只有4GB,所以32位进程的用户态进程地址空间与64位进程是有区别的。32位进程的用户态地址空间是[0x0, 0x00000000FFFF_FFFF]64位进程的用户态地址空间是[0x0, 0x0000FFFFFFFF_FFFF]从代码看出,32bit进程用户空间大小是4GB,64bit进程的虚拟内存大小与CONFIG_ARM64_VA_BITS的值相关;如果CONFIG_ARM64_VA_BITS是48bit则可以达到256TB,现在的移动设备显然用不到这么大的内存空间,所以大部分Android设备中CONFIG_ARM64_VA_BITS默认配置的是39,即64bit进程的最大虚拟地址空间大小是512GB。虽然32bit或者64bit的进程在用户态内存空间大小不一样,但是当它们陷入到内核态后,访问的内核空间地址是没有差异的,都是从VA_START开始,直到0xFFFFFFFFFFFFFFFF结束,也是512GB。每个进程的虚拟地址空间主要分为如下几个区域(如图):参考:https://cloud.tencent.com/developer/article/1647582http://www.360doc.com/content/13/0915/09/8363527_314549128.shtml