搜索到
1
篇与
的结果
-
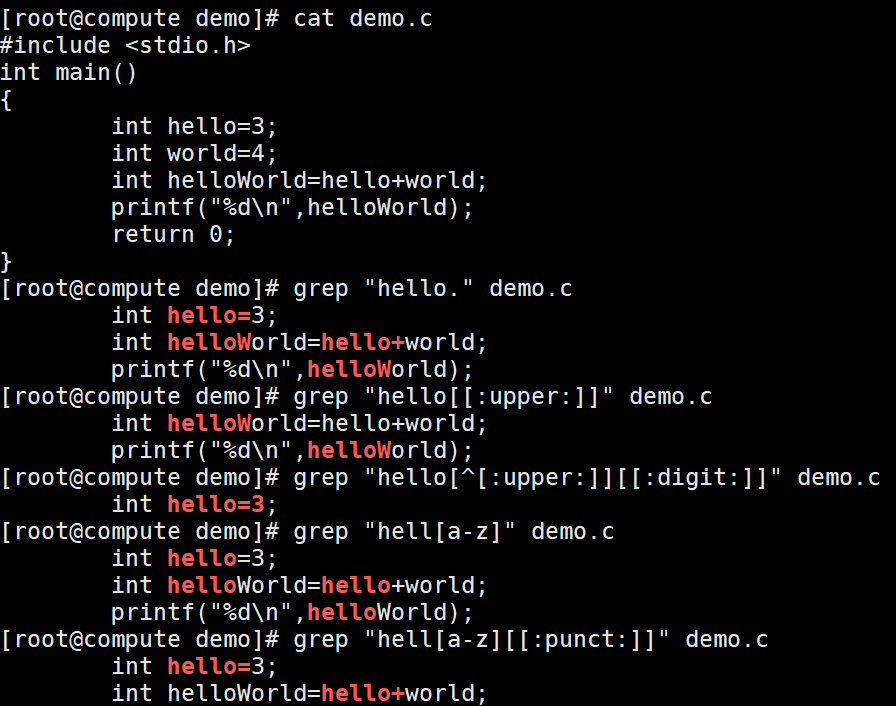
 Linux grep命令 Linux grep命令简介Linux grep 命令用于查找文件里符合条件的字符串。grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。grep家族总共有三个:grep,egrep,fgrep。语法grep [选项] "模式" [文件] grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示行数>][-C<显示行数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...] 参数-a 或 --text : 不要忽略二进制的数据。-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。-c 或 --count : 计算符合样式的列数。-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。-d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。-e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。-E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。-f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。-F 或 --fixed-regexp : 将样式视为固定字符串的列表。-G 或 --basic-regexp : 将样式视为普通的表示法来使用。-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。-i 或 --ignore-case : 忽略字符大小写的差别。-l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。-o 或 --only-matching : 只显示匹配PATTERN 部分。-q 或 --quiet或--silent : 不显示任何信息。-r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。-s 或 --no-messages : 不显示错误信息。-v 或 --invert-match : 显示不包含匹配文本的所有行。-V 或 --version : 显示版本信息。-w 或 --word-regexp : 只显示全字符合的列。比如找like,就不会匹配文本中的liker-x --line-regexp : 只显示全列符合的列。-y : 此参数的效果和指定"-i"参数相同。模式部分直接输入要匹配的字符串,这个可以用fgrep(fast grep)代替来提高查找速度,比如我要匹配一下hello.c文件中printf的个数:fgrep -c "printf" hello.c使用基本正则表达式,下面谈关于基本正则表达式的使用:匹配字符: . :任意一个字符。[abc] :表示匹配一个字符,这个字符必须是abc中的一个。[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。1 :匹配一个字符,这个字符是除了1、2、3以外的所有字符。对于一些常用的字符集,系统做了定义:[A-Za-z] 等价于 [[:alpha:]][0-9] 等价于 [[:digit:]][A-Za-z0-9] 等价于 [[:alnum:]]tab,space 等空白字符 [[:space:]][A-Z] 等价于 [[:upper:]][a-z] 等价于 [[:lower:]]标点符号 [[:punct:]]匹配次数:{m,n} :匹配其前面出现的字符至少m次,至多n次。? :匹配其前面出现的内容0次或1次,等价于{0,1}。:匹配其前面出现的内容任意次,等价于{0,},所以 ".*" 表述任意字符任意次,即无论什么内容全部匹配。位置锚定:^ :锚定行首$ :锚定行尾。技巧" ^$ "用于匹配空白行。\b或\<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker\b或\>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like\B :与\b作用相反。分组及引用:(string) :将string作为一个整体方便后面引用\1 :引用第1个左括号及其对应的右括号所匹配的内容。\2 :引用第2个左括号及其对应的右括号所匹配的内容。\n :引用第n个左括号及其对应的右括号所匹配的内容。扩展的(Extend)正则表达式注意:使用扩展的正则表达式要加-E选项,或者世界使用egrep匹配字符: 与基本正则表达式一样匹配次数::和基本正则表达式一样? :基本正则表达式是?,这里没有\。{m,n} :相比基本正则表达式也是没有了\。:匹配其前面的字符至少一次,相当于{1,}。位置锚定:和基本正则表达式一样。分组及引用:(string) :相比基本正则表达式也是没有了\。\1 :引用部分和基本正则表达式一样。\n :引用部分和基本正则表达式一样。或者:a|b :匹配a或b,注意a是指 | 的左边的整体,b也同理。比如 C|cat 表示的是 C或cat,而不是Cat或cat,如果要表示Cat或cat,则应该写为 (C|c)at 。记住(string)除了用于引用还用于分组。注1:默认情况下,正则表达式的匹配工作在贪婪模式下,也就是说它会尽可能长地去匹配,比如某一行有字符串 abacb,如果搜索内容为 "a.*b" 那么会直接匹配 abacb这个串,而不会只匹配ab或acb。注2:所有的正则字符,如 [ 、* 、( 等,若要搜索 ,而不是想把 解释为重复先前字符任意次,可以使用 * 来转义。参考:Linux grep命令-菜鸟教程linux中grep命令的用法123 ↩
Linux grep命令 Linux grep命令简介Linux grep 命令用于查找文件里符合条件的字符串。grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。grep家族总共有三个:grep,egrep,fgrep。语法grep [选项] "模式" [文件] grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示行数>][-C<显示行数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...] 参数-a 或 --text : 不要忽略二进制的数据。-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。-c 或 --count : 计算符合样式的列数。-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。-d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。-e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。-E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。-f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。-F 或 --fixed-regexp : 将样式视为固定字符串的列表。-G 或 --basic-regexp : 将样式视为普通的表示法来使用。-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。-i 或 --ignore-case : 忽略字符大小写的差别。-l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。-o 或 --only-matching : 只显示匹配PATTERN 部分。-q 或 --quiet或--silent : 不显示任何信息。-r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。-s 或 --no-messages : 不显示错误信息。-v 或 --invert-match : 显示不包含匹配文本的所有行。-V 或 --version : 显示版本信息。-w 或 --word-regexp : 只显示全字符合的列。比如找like,就不会匹配文本中的liker-x --line-regexp : 只显示全列符合的列。-y : 此参数的效果和指定"-i"参数相同。模式部分直接输入要匹配的字符串,这个可以用fgrep(fast grep)代替来提高查找速度,比如我要匹配一下hello.c文件中printf的个数:fgrep -c "printf" hello.c使用基本正则表达式,下面谈关于基本正则表达式的使用:匹配字符: . :任意一个字符。[abc] :表示匹配一个字符,这个字符必须是abc中的一个。[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。1 :匹配一个字符,这个字符是除了1、2、3以外的所有字符。对于一些常用的字符集,系统做了定义:[A-Za-z] 等价于 [[:alpha:]][0-9] 等价于 [[:digit:]][A-Za-z0-9] 等价于 [[:alnum:]]tab,space 等空白字符 [[:space:]][A-Z] 等价于 [[:upper:]][a-z] 等价于 [[:lower:]]标点符号 [[:punct:]]匹配次数:{m,n} :匹配其前面出现的字符至少m次,至多n次。? :匹配其前面出现的内容0次或1次,等价于{0,1}。:匹配其前面出现的内容任意次,等价于{0,},所以 ".*" 表述任意字符任意次,即无论什么内容全部匹配。位置锚定:^ :锚定行首$ :锚定行尾。技巧" ^$ "用于匹配空白行。\b或\<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker\b或\>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like\B :与\b作用相反。分组及引用:(string) :将string作为一个整体方便后面引用\1 :引用第1个左括号及其对应的右括号所匹配的内容。\2 :引用第2个左括号及其对应的右括号所匹配的内容。\n :引用第n个左括号及其对应的右括号所匹配的内容。扩展的(Extend)正则表达式注意:使用扩展的正则表达式要加-E选项,或者世界使用egrep匹配字符: 与基本正则表达式一样匹配次数::和基本正则表达式一样? :基本正则表达式是?,这里没有\。{m,n} :相比基本正则表达式也是没有了\。:匹配其前面的字符至少一次,相当于{1,}。位置锚定:和基本正则表达式一样。分组及引用:(string) :相比基本正则表达式也是没有了\。\1 :引用部分和基本正则表达式一样。\n :引用部分和基本正则表达式一样。或者:a|b :匹配a或b,注意a是指 | 的左边的整体,b也同理。比如 C|cat 表示的是 C或cat,而不是Cat或cat,如果要表示Cat或cat,则应该写为 (C|c)at 。记住(string)除了用于引用还用于分组。注1:默认情况下,正则表达式的匹配工作在贪婪模式下,也就是说它会尽可能长地去匹配,比如某一行有字符串 abacb,如果搜索内容为 "a.*b" 那么会直接匹配 abacb这个串,而不会只匹配ab或acb。注2:所有的正则字符,如 [ 、* 、( 等,若要搜索 ,而不是想把 解释为重复先前字符任意次,可以使用 * 来转义。参考:Linux grep命令-菜鸟教程linux中grep命令的用法123 ↩