搜索到
383
篇与
的结果
-
 网站异常问题记录 网络异常问题现象流量一直在跑解决找到是哪些ip,然后禁止访问使用iftop查看网络流量sudo iftop -i eth0使用下面的命令从log文件中找到是哪些异常ip注意:根据实际情况调整grep的值cat ahutxl.cn.log | grep "\.zip" | awk '{print $1}' | sort | uniq -c | sort -nr | head 有大量的google bot的访问我的图床网站,之前是facebook的,把这个66.249开头的都禁止掉访问使用下面的命令sudo iptables -A INPUT -s 66.249.0.0/16 -j DROP 如果用的是宝塔面板,从宝塔面板里面添加也是一样的。无论如何要确保添加的规则有生效才行禁止这些bot后负载就基本正常了chatgpt:如果你想禁止所有来自 69.171.*.* 范围的 IP,可以使用以下命令:sudo iptables -A INPUT -s 69.171.0.0/16 -j DROP详细解释69.171.0.0/16 表示 IP 范围 69.171.0.0 到 69.171.255.255。-A INPUT 表示添加一条规则到 INPUT 链。-s 69.171.0.0/16 指定来源 IP 地址范围。-j DROP 表示丢弃匹配到的所有数据包。验证规则在添加规则后,你可以使用以下命令查看当前的 iptables 规则,以确认规则是否已经生效:sudo iptables -L -v -n删除规则如果你以后想要删除这条规则,可以使用以下命令:sudo iptables -D INPUT -s 69.171.0.0/16 -j DROP保存规则确保规则在重启后依然有效,可以使用以下命令保存规则:对于 Debian/Ubuntu:sudo apt-get install iptables-persistent sudo netfilter-persistent save对于 CentOS/Red Hat:sudo yum install iptables-services sudo service iptables save这样设置之后,所有来自 69.171.*.* 的流量将被阻止访问你的服务器。
网站异常问题记录 网络异常问题现象流量一直在跑解决找到是哪些ip,然后禁止访问使用iftop查看网络流量sudo iftop -i eth0使用下面的命令从log文件中找到是哪些异常ip注意:根据实际情况调整grep的值cat ahutxl.cn.log | grep "\.zip" | awk '{print $1}' | sort | uniq -c | sort -nr | head 有大量的google bot的访问我的图床网站,之前是facebook的,把这个66.249开头的都禁止掉访问使用下面的命令sudo iptables -A INPUT -s 66.249.0.0/16 -j DROP 如果用的是宝塔面板,从宝塔面板里面添加也是一样的。无论如何要确保添加的规则有生效才行禁止这些bot后负载就基本正常了chatgpt:如果你想禁止所有来自 69.171.*.* 范围的 IP,可以使用以下命令:sudo iptables -A INPUT -s 69.171.0.0/16 -j DROP详细解释69.171.0.0/16 表示 IP 范围 69.171.0.0 到 69.171.255.255。-A INPUT 表示添加一条规则到 INPUT 链。-s 69.171.0.0/16 指定来源 IP 地址范围。-j DROP 表示丢弃匹配到的所有数据包。验证规则在添加规则后,你可以使用以下命令查看当前的 iptables 规则,以确认规则是否已经生效:sudo iptables -L -v -n删除规则如果你以后想要删除这条规则,可以使用以下命令:sudo iptables -D INPUT -s 69.171.0.0/16 -j DROP保存规则确保规则在重启后依然有效,可以使用以下命令保存规则:对于 Debian/Ubuntu:sudo apt-get install iptables-persistent sudo netfilter-persistent save对于 CentOS/Red Hat:sudo yum install iptables-services sudo service iptables save这样设置之后,所有来自 69.171.*.* 的流量将被阻止访问你的服务器。 -
-
-
[转载]armv8/armv9中断系列详解-中断示例展示 一、中断示例展示(不含虚拟化部分)环境配置:在linux/optee双系统环境下, linux系统的SCR.IRQ=0、SCR.FIQ=1, optee系统的SCR.IRQ=0、SCR.FIQ=0Linux 系统普通中断被路由到普通世界(即 Linux 系统), 快速中断被路由到安全世界(即 OP-TEE 系统)。当系统处于安全世界(即 OP-TEE 系统)时,所有中断(包括普通中断和快速中断)都被路由回普通世界。这允许在 OP-TEE 中执行安全操作时,中断可以被普通世界(即 Linux 系统)处理,确保安全世界的操作不中断。说明:group1是非安全中断、secure group1是安全中断1、当cpu处于REE,来了一个非安全中断当cpu处于normal侧时,来了一个非安全中断,根据SCR.NS=1/中断在group1组,cpu interface将会给cpu一个IRQ,(由于SCR.IRQ=0,IRQ将被routing到EL1),cpu跳转至linux的irq中断异常向量表, 处理完毕后再返回到normal(linux)侧.2、当cpu处于TEE,来了一个安全中断当cpu处于secure侧时,来了一个安全中断,根据SCR.NS=0/中断在secure group1组,cpu interface将会给cpu一个IRQ,(由于SCR.IRQ=0,IRQ将被routing到EL1),cpu跳转至optee的irq中断异常向量表, 处理完毕后再返回到secure(optee)侧.3、当cpu处于TEE,来了一个非安全中断当cpu处于secure侧时,来了一个非安全中断,根据SCR.NS=0/中断在group1组,cpu interface将会给cpu一个FIQ,(由于SCR.FIQ=0,FIQ将被routing到EL1),跳转至optee的fiq中断异常向量表,在optee的fiq处理函数中,直接调用了smc跳转到ATF, ATF再切换至normal EL1(linux), 此时SCR.NS的状态发生变化,根据SCR.NS=1/中断在group1组,cpu interface会再给cpu发送一个IRQ异常,cpu跳转至linux的irq中断异常向量表,处理完毕后,再依次返回到ATF---返回到optee4、当cpu处于REE,来了一个安全中断当cpu处于normal侧时,来了一个安全中断,根据SCR.NS=0/中断在group1组,cpu interface将会给cpu一个FIQ,(由于SCR.FIQ=1,FIQ将被routing到EL3),在EL3(ATF)中,判断该中断是需要optee来处理的,会切换到optee。此时SCR.NS的状态发生变化,根据SCR.NS=0/中断在secure group1组,cpu interface会再给cpu发送一个IRQ异常,cpu跳转至optee的irq中断异常向量表, 处理完毕后再依次返回到ATF---返回到linux5、当cpu处于ATF时,来了一个安全中断或非安全中断(G1NS、G1S)当cpu处于EL3时,来得任何target到EL3的中断,都将被标记位FIQ当cpu处于EL3时,配置SCR.XXX(XXX=EA或IRQ或FIQ)为0的中断不会被taken,配置SCR.XXX为1的中断将会直接target到EL3。所以在 linux系统的SCR.IRQ=0、SCR.FIQ=1, optee系统的SCR.IRQ=0、SCR.FIQ=0的场景下,总结如下,当cpu运行在EL3时:SCR_EL3为optee的cpu context时,来了一个G1S,中断将不会被takenSCR_EL3为optee的cpu context时,来了一个G1NS,中断将不会被takenSCR_EL3为linux的cpu context时,来了一个G1S,中断将会直接target到EL3SCR_EL3为linux的cpu context时,来了一个G1NS,中断将不会被taken6、当cpu处于EL3/EL2/EL1/EL0时,来了一个ATF(group0)中断(G0)当cpu处于EL3/EL2/EL1/EL0时,来了一个G0中断,中断将被标记位FIQ在 linux系统的SCR.IRQ=0、SCR.FIQ=1, optee系统的SCR.IRQ=0、SCR.FIQ=0的场景下,总结如下:当cpu正在Non-secure EL0/1/2运行时,来了G0中断,中断被标记为FIQ,直接target到EL3当cpu正在secure EL0/1/2运行时,来了G0中断,中断被标记为FIQ,中断target到了EL0/1/2,在该程序的fiq_offset会调用smc将cpu切回到EL3,到了EL3之后,中断不会被taken, 会继续返回到Non-secure EL0/1/2,然后cpu interface重新给core发送FIQ,接着又是直接target到EL3,EL3处理该中断。当cpu正在EL3时,来了一个G0中断,中断会被标记为FIQ,中断target到EL3。7、思考-中断流程举例:在TEE侧时产生了FIQ,回到REE后为啥又产生了IRQ在深入研读GICV3文档后,终于找到了答案。首先我们了解下中断优先级,在CPU interfaces (ICC*ELn)寄存器的描述中:• Provide general control and configuration to enable interrupt handling• Acknowledge an interrupt• Perform a priority drop and deactivation of interrupts• Set an interrupt priority mask for the PE• Define the preemption policy for the PE• Determine the highest priority pending interrupt for the PE也就是cpu interface掌管着中断优先级和将IRQ/FIQ发送给ARM Core.我们以Level sensitive interrupts的中断为例,先不考虑active and pending的情况:CPU interface发送给Core后,中断状态变为pending,当Core acknowledge中断后(PE跳转到中断向量表), 中断状态变为active,当中断退出后,Cpu interface会再次将优先级最高的中断发送给Core,Core处理下一个中断。我们再看下中断的退出流程( End of interrupt), 中断的退出有两种方式:• Priority drop 将中断优先级降到中断产生之前的值• Deactivation 将中断从active变成inactive -- ( 多数情况下,使用这个场景)重点来了,在中断退出的时候,软件中一般会有Priority drop和Deactivation,既要么将中断优先级降低,要么将中断变为inactive,那么中断退出之后,cpu interface感知到的优先级最高的中断,就可能不会是此中断了,一切运行正常,符合业务.....那么我们再看下上述的中断流程举例,在TEE中,cpu interface发了一个FIQ给Core,跳转到optee的FIQ向量表,在FIQ的处理流程中,软件几乎什么都没干,没有Priority drop和Deactivation, 那么当SMC切换到了EL3之后,又退回REE后,Cpu interface感知到上一个中断处理完成,会再次发送下一个优先级最高的中断,由于之前的中断号的优先级没变,此时基本上依然是最高的优先级。此时CPU interface会再次发送该中断给Core,由于SCR.NS发生了变化,此时Cpu interface发送给Core的就变成了IRQ...8、思考-G1NS G1S G0都有可能产生target到EL3的FIQ,如何区分?其实在我们的linux系统的SCR.IRQ=0、SCR.FIQ=1, optee系统的SCR.IRQ=0、SCR.FIQ=0的场景下,不考虑aarch32的情况,有两种情况会产生target到EL3的FIQ:(1)cpu在EL0/1/2运行时,来了一个G0中断,最终CPU将会进入到EL3的向量表中的第三组向量表。(2)cpu在EL3运行时,来了一个G0中断,最终CPU将会进入到EL3的向量表中的第二组向量表 不过很遗憾,ATF中的向量表中未实现第二组向量表。那么为什么不需要实现呢?在ATF/docs/firmware-design.md中找到了答案, 原来是在进入ATF之前,disable了所有的exception,ATF又没有修改PSTATE.DAIF,所有在ATF Runtime时 irq/fiq/serror/svnc都是disabled。所以异常向量表的第二行,也就用不着了。Required CPU state when calling bl31_entrypoint() during cold boot This function must only be called by the primary CPU. On entry to this function the calling primary CPU must be executing in AArch64 EL3, little-endian data access, and all interrupt sources masked: PSTATE.EL = 3 PSTATE.RW = 1 PSTATE.DAIF = 0xf SCTLR_EL3.EE = 0(3)cpu在normal EL0/1/2/3运行时(Linux侧的SCR_EL3.FIQ=1的情况下),来了一个G1S中断,CPU将会target到EL3的向量表中的第三组向量表。那么在ATF中第三组向量表中的fiq offset中,是如何区分上述(1)(3)中的场景呢,即如何区分该中断是给EL3 handler处理的,还是给optee的handler处理的?此时1020-1023号中断发生了作用。我们应该会用到1020,那么用在哪里的呢?请看上述汇编代码bl plat_ic_get_pending_interrupt_type的具体实现:uint32_t plat_ic_get_pending_interrupt_type(void) { unsigned int irqnr; assert(IS_IN_EL3()); irqnr = gicv3_get_pending_interrupt_type(); switch (irqnr) { case PENDING_G1S_INTID: return INTR_TYPE_S_EL1; case PENDING_G1NS_INTID: return INTR_TYPE_NS; case GIC_SPURIOUS_INTERRUPT: return INTR_TYPE_INVAL; default: return INTR_TYPE_EL3; } }其实就是在读取pending的中断号,看看有没有1020或1021,从而获得此次的中断是从secure或non-secure过来的,还是在EL3产生的。然后走相应的逻辑。二、中断示例展示(虚拟化部分)影响中断routing的相关控制位主要是 HCR_EL2.IMO/FMO/AMO(本文只探讨irq/virq,所以我们只看 IMO比特位),除此之外还有HCR_EL2.TGE比特位影响Application是做为Host还是Guest.以下是这些比特位的路由规则的总结:我们学习了其原理之后,我们再看4个示例:(1)、HCREL2.IMO=1 , HCREL2.TGE=1 --routing到EL2,Application做为Guest(2)、HCREL2.IMO=1 , HCREL2.TGE=0 --routing到EL2,Application做为Host(3)、HCREL2.IMO=0 , HCREL2.TGE=1 --routing到EL1,Application做为Guest(4)、HCREL2.IMO=0 , HCREL2.TGE=0 --routing到EL1,Application做为host
-
-
-
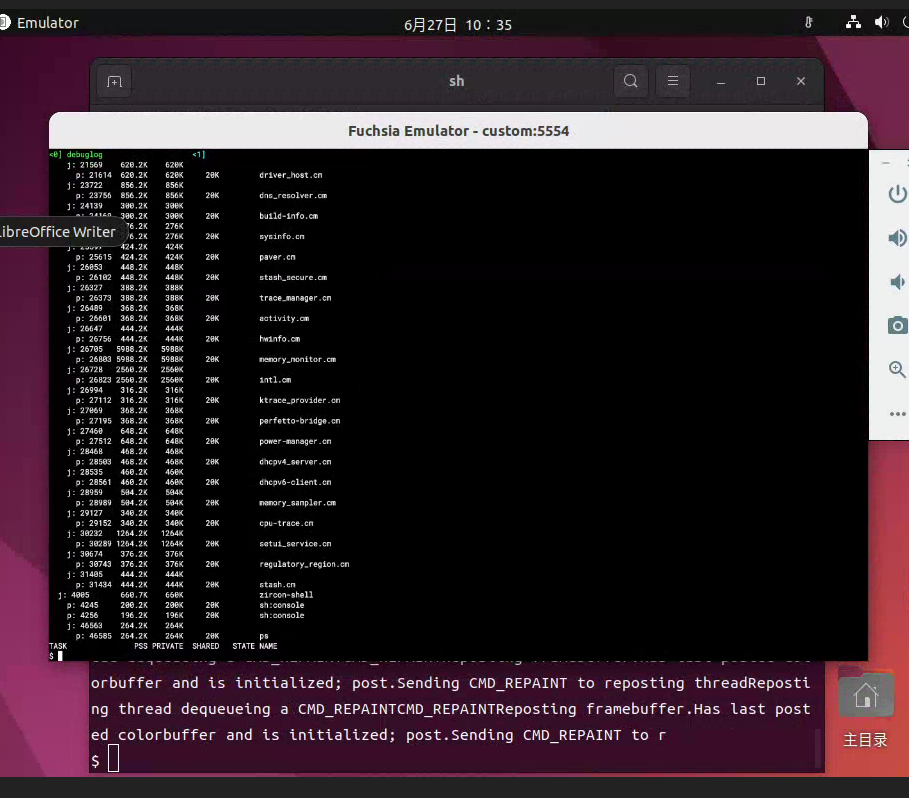
fuchsia os环境配置记录 fuchsia开发者文档还是比较完善的,具体细节可以直接去看官方文档1. 代码下载下面这个可以直接下载到fuchsia整个源码,在同一个git仓库中,如果只是查看源码可以用这个。git clone https://fuchsia.googlesource.com/fuchsia否则还是根据fuchsia网站上的下载方式下载代码吧。curl -s "https://fuchsia.googlesource.com/fuchsia/+/HEAD/scripts/bootstrap?format=TEXT" | base64 --decode | bash代码下载完成后,将jiri和fx添加到环境变量中,方便使用。export PATH=$PATH:/home/user/tanxl/github/fuchsia/.jiri_root/bin/ export PATH=$PATH:/home/user/tanxl/github/fuchsia/scripts/ source /home/user/tanxl/github/fuchsia/scripts/fx-env.sh网不好的话prebuilt包可能拉不下来,可以jiri update更新,加上时间,默认应该是20分钟,可以延长到600分钟。jiri update -fetch-packages-timeout=6002. 代码编译例如,一个基础的模拟器启动流程 $ fx set core.x64 --with //examples/hello_world $ fx build $ fx ffx emu start --headless --net tap # headless with tun/tap-based networking // 也可以只用启动console,不用网络 $ fx ffx emu start --console $ fx serve # [Start in a new window] $ fx test hello-world-cpp-unittests # [Start in a new window] Run test $ fx ffx emu stop # Shut down the emulator 启动效果如下,启动其他product示例fx set workbench_eng.x64 --release fx build fx serve // FUCHSIA_ROOT 是 Fuchsia 目录的路径。 ffx config set emu.upscript FUCHSIA_ROOT/scripts/start-unsecure-internet.sh // 如需启动能够访问外部网络的模拟器,请运行以下命令: ffx emu start --net tap // 如需在无法访问外部网络的情况下启动模拟器,请运行以下命令: ffx emu start --net none
-
Arm64体系架构-MPIDR_EL1寄存器 背景在Arm64多核处理器中, 各核间的关系可能不同. 比如1个16 core的cpu, 每4个core划分为1个cluster,共享L2 cache. 当我们需要从core 0将任务调度出来时,如果优先选择core 1~3, 那么性能明显时优于其他core的.那么操作系统怎么知道core之间这样的拓扑信息呢? Arm提供了MPIDR_EL1 寄存器. 每个core都有一个该寄存器。字段说明a.该寄存器为只读寄存器b.AFF3 & AFF2 都为ClusterID(从软件角度理解为不同CPU组的ID),AFF1 为CPUID,AFF0 为多线程核的线程ID(指的是是否支持超线程的id)MPIDR_EL1U, bit [30]0表示多核处理, 1表示单核处理MT, bit [24]0表示没有使用单核超线程, 1表示使用了单核超线程。其他的affinity,则表示了各核之间的亲和性。以一个8核2 cluster 非超线程cpu为例, core0的mpidr_el1的affinity为(0,0,0,0),core1为(0,0,0,1),以次类推, core7则为(0,0,1,3)。Arm规范要求了每个core的(Aff3,Aff2,Aff1,Aff0)编码必须唯一。不支持超线程的cpu, Aff0表示核id这样通过树形结构的编码,OS可以从该寄存器中获取各core之间的关系。kernel 应用// kernel表示每个core的拓扑结构,每个core对应一个该结构 struct cpu_topology { int thread_id; int core_id; int package_id; int llc_id; cpumask_t thread_sibling; cpumask_t core_sibling; cpumask_t llc_sibling; }; void store_cpu_topology(unsigned int cpuid) { struct cpu_topology *cpuid_topo = &cpu_topology[cpuid]; // 读取MPIDR_EL1 u64 mpidr = read_cpuid_mpidr(); /* Create cpu topology mapping based on MPIDR. */ // 判断芯片是否支持超线程 if (mpidr & MPIDR_MT_BITMASK) { /* Multiprocessor system : Multi-threads per core */ // 在支持超线程的cpu, Aff0表示一个core内的超线程id cpuid_topo->thread_id = MPIDR_AFFINITY_LEVEL(mpidr, 0); cpuid_topo->core_id = MPIDR_AFFINITY_LEVEL(mpidr, 1); // package_id即cluster id cpuid_topo->package_id = MPIDR_AFFINITY_LEVEL(mpidr, 2) | MPIDR_AFFINITY_LEVEL(mpidr, 3) << 8; } else { /* Multiprocessor system : Single-thread per core */ cpuid_topo->thread_id = -1; // 不支持超线程的cpu, Aff0表示核id cpuid_topo->core_id = MPIDR_AFFINITY_LEVEL(mpidr, 0); cpuid_topo->package_id = MPIDR_AFFINITY_LEVEL(mpidr, 1) | MPIDR_AFFINITY_LEVEL(mpidr, 2) << 8 | MPIDR_AFFINITY_LEVEL(mpidr, 3) << 16; } ... ... }MPIDR_EL1在devicetree中的体现配置DTS时,需要设置MPIDR_EL1的值到CPU node中的reg property,以ArmV8 64bit系统为例:当#address-cell property为2时,需要设置MPIDR_EL1[39:32]到第一个reg cell的reg[7:0]、MPIDR_EL1[23:0]到第二个reg celll的reg[23:0]; 当#address-cellproperty为1时,需要设置MPIDR_EL1[23:0]到reg[23:0];reg的其他位设置位0。Linux启动过程中MPIDR_EL1的相关逻辑 a.内核中定义了cpu的逻辑映射变量如下,该变量保存MPIDR_EL1寄存器中亲和值。 /* * Logical CPU mapping. */ extern u64 __cpu_logical_map[NR_CPUS]; #define cpu_logical_map(cpu) __cpu_logical_map[cpu] b.cpu0(boot cpu/primary cpu)获取mpidr_el1亲和值的方式与其他cpu(secondary cpu) 获取方式有所不同。 void __init smp_setup_processor_id(void) { /*启动该过程时只有boot cpu即cpu0在执行,其他cpu还未启动 通过read_cpuid_mpidr获取的MPIDR_EL1值即为当前执行的CPU0 的亲和值*/ u64 mpidr = read_cpuid_mpidr() & MPIDR_HWID_BITMASK; /*将获取到的cpu0的亲和值保存在cpu_logical_map(0)*/ cpu_logical_map(0) = mpidr; /* * clear __my_cpu_offset on boot CPU to avoid hang caused by * using percpu variable early, for example, lockdep will * access percpu variable inside lock_release */ set_my_cpu_offset(0); pr_info("Booting Linux on physical CPU 0x%lx\n", (unsigned long)mpidr); }
-
ARM WFI和WFE指令 转载自https://zhuanlan.zhihu.com/p/6860633741.基本介绍ARM有两条和低功耗相关的指令: WFI和WFE。WFI全称是Wait For Interrupt,WFE全称是Wait For Event。这两条指令统称为WFx,可以让ARM核进入low-power standby模式,由ARM架构定义,由ARM core实现,使用时不需要带任何参数。ARM架构并没有规定“low-power standby state”的具体形式,可以由ARM core自定义实现,根据ARM的建议,一般可以实现为standby(关闭clock、保持供电)、dormant、shutdown等。但有个原则,不能造成内存一致性的问题。以Cortex-A57 ARM core为例,它把WFI和WFE实现为“put the core in a low-power state by disabling the clocks in the core while keeping the core powered up”,即我们通常所说的standby模式,保持供电,关闭clock。接下来了解一下ARM处理器进入低功耗状态的机制。当一个处理器核的工作负载不高时,可以通过降压降频(DVFS)的方式来让处理器运行在较低频率,从而降低芯片功耗。如果处理器没有工作负载,完全空闲下来,这时就需要让处理器进入更低的功耗模式。CPU进入空闲状态的大概顺序如下:应用处理器(Application Processor)判断是否具备进入空闲状态的条件,如果满足条件则进行一些准备工作;发消息给系统控制器(System control processor);等待全部操作执行完;执行WFI进入空闲状态;等待系统控制器做出下一步动作,或者关闭时钟,或者关闭电源等等。从WFI的名字可以看出,唤醒(wake up)处理器的一个机制就是发送中断给处理器(也有一些其他的机制)。GIC中断控制器接收到中断后,产生唤醒信号给系统控制器或者是电源管理模块(Power Management Unit),系统控制器或者PMU根据处理器核的状态以及系统状态,决定下一步的动作。WFE与WFI类似,只不过等待的是事件,也就是说系统可以通过发送事件来唤醒CPU核。WFE的一个典型应用场景是自旋锁spinlock。当多个核竞争同一个临界区资源时,只有一个核能获得权限,其它的核需要等待临界区资源被释放,也就是这些核“自旋”。当然操作系统也可以采取其它的处理方式,比如把时间片分给其它的应用程序。显然,应用处理器简单的“自旋”对于功耗不友好,一个解决办法就是让这些“自旋”的核进入低功耗模式,获得临界区资源的核在完成当前进程后,唤醒这些核去重新竞争临界区资源。这时的唤醒机制不宜采取中断方式,因为效率不高。ARM采用的是事件方式,即通过执行SEV(Send Event)指令向其它应用处理器发送唤醒的事件。WFI和WFE还有一种变体形式,WFIT和WFET,其中的T是超时(timeout)的意思,也就是说,唤醒机制多了一种超时的方式,没有中断或者事件产生,时间到了也会发出唤醒。2.不同点WFE状态的唤醒事件比WFI多了一个SEV指令(Send Event),也就是说WFE还会受控于一个1bit event register,此寄存器软件不可访问。此功能时为多核而准备的。WFE在event register为0,或为1时,其功能是不一样的。WFE的E就是指这个事件寄存器。进一步描述:假设两个核,分别为core1和core2,A、core1可以执行SEV指令更改event register,同时它可以通过TXEV硬连接到core2的RXEV更改core2的event register。 B、core1在执行WFE时,如果发现event register=1,它是不会进低功耗的,这里就是区别。 基于以上描述WFE是多核低功耗用的,举个例子:当core1和core2抢同一个资源A时,core1占据A,那core2就WFE进低功耗,等待core1的SEV发过来。SEV指令是一个用来改变Event Register的指令,有两个:SEV会修改所有PE上的寄存器;SEVL只修改本PE的寄存器值。3.使用场景1)WFIWFI一般用于cpu idle。在ARM64架构中,当CPU Idle时,会调用WFI指令,关掉CPU的Clock以便降低功耗。2)WFEWFE的典型使用场景是在spinlock中(可参考arch_spin_lock,对arm64来说,位于arm64/include/asm/spinlock.h中)。spinlock的功能,是在不同CPU core之间,保护共享资源。使用WFE的流程是:1. 资源空闲 2. Core1访问资源,acquire lock,获得资源 3. Core2访问资源,此时资源不空闲,执行WFE指令,让core进入low-power state 4. Core1释放资源,release lock,释放资源,同时执行SEV指令,唤醒Core2 5. Core2获得资源
-


![[转载]armv8/armv9中断系列详解-optee运行时来了一个REE(linux)中断--代码导读](https://ahutxl.cn/images/2024/08/06/imagebc77baaa6423bced.png)
![[转载]armv8/armv9中断系列详解-中断示例展示](https://ahutxl.cn/images/2024/08/06/image4b22a3dca236bb2e.png)
![[转载]armv8-armv9 中断系列详解--硬件基础篇](https://ahutxl.cn/images/2024/08/06/image.png)