搜索到
384
篇与
的结果
-
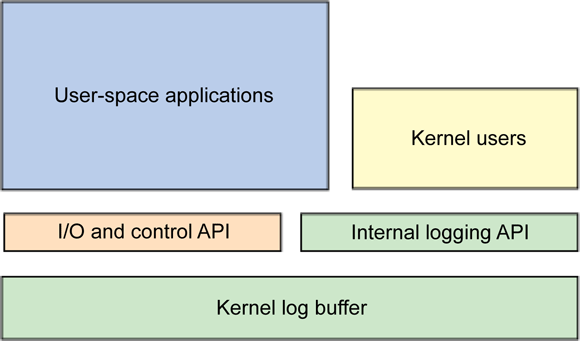
 内核日志:API及实现 [TOC]内核版本:Linux5.4.0本文首先通过介绍用于配置和收集日志信息的应用程序接口(API)来说明了内核的日志(见图 1 关于总结框架和组件的示意图)。然后,本文介绍了日志数据从内核到用户空间的移动过程。最后,本文还介绍了基于内核的日志数据的目标:用户空间中使用 rsyslog 进行日志管理。内核API内核的日志是通过 printk 函数实现的,它与用户空间对应函数 printf(按格式打印)具有相似的作用。printf 命令在编程语言中已存在很长时间,最近出现是在 C 语言中,但是最早出现可以追溯到 50 年代和 60 年代的 Fortran(PRINT 和 FORMAT 语句)、BCPL(writf 函数;BCPL 是 C 的前身)和 ALGOL 68 语言(printf 和 putf)。在内核中,printk(打印内核)可以使用与 printf 函数几乎一样的格式将将格式化消息写入到缓冲区。您可以在 ./linux/include/linux/kernel.h(及其实现 ./linux/kernel/printk.c)中看到 printk 的格式:int printk( const char * fmt, ... );这个格式表示的是一个用于定义文本和格式的字符串(类似于 printf),它同时带有一组可变个数参数(由省略号表示 [...])。内核配置与错误通过 printk 实现的日志是通过内核配置选项 CONFIG_PRINTK 激活的。虽然 CONFIG_PRINTK 一般都是激活的,但是不包含这个选项的系统对内核的调用会返回一个 ENOSYS 错误返回值。在使用 printk 时,您首先会发现的不同点更多是关于协议,而不是功能的。这个特性使用了 C 语言的一种模糊方面来简化消息级别和优先级的规范。内核允许每一个消息根据日志级别(定义不同消息重要必的八种级别之一)来分类。这些级别可以用来判断系统是否不可用(紧急消息)、是否发现严重状况(严重消息)或者是否为简单报告消息。 这个内核代码直接将日志级别定义消息的第一个参数,下面这个例子说明的就是严重消息的定义:printk( KERN_CRIT "Error code %08x.\n", val );注意,第一个参数并不一个真正的参数,因为其中没有用于分隔级别(KERN_CRIT)和格式字符的逗号(,)。KERN_CRIT 本身只是一个普通的字符串(事实上,它表示的是字符串 "2";表 1 列出了完整的日志级别清单)。作为预处理程序的一部分,C 会自动地使用一个名为 字符串串联 的功能将这两个字符串组合在一起。组合的结果是将日志级别和用户指定的格式字符串包含在一个字符串中。注意,如果调用者未将日志级别提供给 printk,那么系统就会使用默认值 KERN_WARNING(表示只有 KERN_WARNING 级别以上的日志消息会被记录。)在头文件include/linux/kernel_levels.h里面,定义了日志级别和使用方法:// 位置:include/linux/kernel_levels.h #define KERN_SOH "\001" /* ASCII Start Of Header */ #define KERN_SOH_ASCII '\001' #define KERN_EMERG KERN_SOH "0" /* system is unusable */ #define KERN_ALERT KERN_SOH "1" /* action must be taken immediately */ #define KERN_CRIT KERN_SOH "2" /* critical conditions */ #define KERN_ERR KERN_SOH "3" /* error conditions */ #define KERN_WARNING KERN_SOH "4" /* warning conditions */ #define KERN_NOTICE KERN_SOH "5" /* normal but significant condition */ #define KERN_INFO KERN_SOH "6" /* informational */ #define KERN_DEBUG KERN_SOH "7" /* debug-level messages */ #define KERN_DEFAULT KERN_SOH "d" /* the default kernel loglevel */printk可以在内核的任意上下文中调用。这个调用从 ./linux/kernel/printk.c 中的 printk 函数开始,它会在使用 va_start 解析可变长度参数之后调用 vprintk(在同一个源文件)。printk函数的实现如下:asmlinkage __visible int printk(const char *fmt, ...) { va_list args; // 可变参数 int r; va_start(args, fmt); r = vprintk_func(fmt, args); va_end(args); return r; } EXPORT_SYMBOL(printk);其中vprintk_func()函数定以如下:__printf(1, 0) int vprintk_func(const char *fmt, va_list args) { /* * Try to use the main logbuf even in NMI. But avoid calling console * drivers that might have their own locks. */ if ((this_cpu_read(printk_context) & PRINTK_NMI_DIRECT_CONTEXT_MASK) && raw_spin_trylock(&logbuf_lock)) { int len; len = vprintk_store(0, LOGLEVEL_DEFAULT, NULL, 0, fmt, args); raw_spin_unlock(&logbuf_lock); defer_console_output(); return len; } /* Use extra buffer in NMI when logbuf_lock is taken or in safe mode. */ if (this_cpu_read(printk_context) & PRINTK_NMI_CONTEXT_MASK) return vprintk_nmi(fmt, args); /* Use extra buffer to prevent a recursion deadlock in safe mode. */ if (this_cpu_read(printk_context) & PRINTK_SAFE_CONTEXT_MASK) return vprintk_safe(fmt, args); /* No obstacles. */ return vprintk_default(fmt, args); }vprintk 函数执行了许多管理级检查(递归检查),然后获取日志缓冲区的锁(\_\_log_buf)。接下来,它会对输入的字符串进行日志级别检查; 如果发现日志级别信息,那么对应的日志级别就会被设置。最后,vprintk 会获取当前时间(使用函数 cpu_clock)并使用 sprintf(不是标准库版本,而是在 ./linux/lib/vsprintf.c 中实现的内部内核版本)将它转换成一个字符串。这个字符串会被传递给 printk,然后它会被一个管理缓冲边界(emit_log_char)的特殊函数复制到内核日志缓冲区中。这个函数最后将获取和释放执行控制台信号,并将下一条日志消息发送到控制台(在 release_console_sem 中执行)。内核缓冲缓冲区的大小初始值为 4KB,但是最新的内核大小已经升级到 16KB(在不同的体系架构上,这个值最高可以达到 1MB)。日志辅助函数内核也提供了一些日志辅助函数,它们可以简化日志函数的使用。每一个日志级别都有一个对应的函数,它会扩展为 printk 函数的一个宏。例如,如果要使用 printk 处理 KERN_EMERG 日志级别时,您可以直接使用 pr_emerg。所有宏都已列在 ./linux/include/linux/kernel.h 文件中。至此,您已经了解用于将日志消息插入到内核环缓冲区的 API。现在,让我们讨论一下用于将数据从内核移动到用户空间的方法。内核日志与接口多用途的 syslog 系统调用提供了内核的日志缓冲区访问方法。这个调用执行了很多个操作,所有操作都可以在用户空间执行,但是只有一个操作可以被非 root 用户执行。syslog 系统调用的原型定义位于 ./linux/include/linux/syslog.h;而它的实现位于 ./linux/kernel/printk.c。syslog 调用是作为内核日志消息环缓冲区的输入/输出(I/O)和控制接口。通过 syslog 调用,应用程序可以读取日志消息(部分、整体或者只读取新消息), 以及控制环缓冲区的行为(清除内容、设置日志的消息级别、启用或禁用控制台等等)。图 2 用图形说明了使用所讨论的主要组件进行日志记录的过程。syslog 调用(在内核中调用 ./linux/kernel/printk.c 的 do_syslog)是一个相对较小的函数,它能够读取和控制内核环缓冲区。注意在 glibc 2.0 中,由于词汇 syslog 使用过于广泛,这个函数的名称被修改成 klogctl,它指的是各种调用和应用程序。syslog 和 klogctl(在用户空间中)的原型函数定义为:int syslog( int type, char *bufp, int len ); int klogctl( int type, char *bufp, int len );type 参数是用于传递所执行的命令,它指定了可选的缓冲区长度。有一些命令(如清除环缓冲)是忽略 bufp 和 len 这两个参数的。虽然前面两个命令类型不会对内核进行任何操作,但是其余命令则是用于读取日志消息或控制日志。其中有三个命令是用于读取日志消息的。SYSLOG_ACTION_READ 用于阻塞操作,直至日志消息到达后才释放该操作,然后将它们返回到所提供的缓冲区。这个命令会处理这些消息(旧的消息将不会出现在这个命令的后续调用中。)SYSLOG_ACTION_READ_ALL 命令会从日志读取最后 n 个字符(而 n 是在传递给 klogctl 的参数 'len' 中定义的)。SYSLOG_ACTION_READ_CLEAR 命令会先执行 SYSLOG_ACTION_READ_ALL 操作,然后执行 SYSLOG_ACTION_CLEAR 命令(清除环缓冲区)。SYSLOG_ACTION_CONSOLE ON 和 OFF 可以将日志级别设置为激活或禁用日志消息输出到控制台,而 SYSLOG_CONSOLE_LEVEL 则允许调用者定义控制台所接受的日志消息级别。最后,SYSLOG_ACTION_SIZE_BUFFER 是用于返回内核环缓冲区大小,而 SYSLOG_ACTION_SIZE_UNREAD 则返回当前内核环缓冲区可读取的字符数。表 2 显示了 SYSLOG 命令的完整清单。使用 syslog/klogctl 系统调用实现的命令:#ifndef _LINUX_SYSLOG_H #define _LINUX_SYSLOG_H /* Close the log. Currently a NOP. */ #define SYSLOG_ACTION_CLOSE 0 /* Open the log. Currently a NOP. */ #define SYSLOG_ACTION_OPEN 1 /* Read from the log. */ #define SYSLOG_ACTION_READ 2 /* Read all messages remaining in the ring buffer. */ #define SYSLOG_ACTION_READ_ALL 3 /* Read and clear all messages remaining in the ring buffer */ #define SYSLOG_ACTION_READ_CLEAR 4 /* Clear ring buffer. */ #define SYSLOG_ACTION_CLEAR 5 /* Disable printk's to console */ #define SYSLOG_ACTION_CONSOLE_OFF 6 /* Enable printk's to console */ #define SYSLOG_ACTION_CONSOLE_ON 7 /* Set level of messages printed to console */ #define SYSLOG_ACTION_CONSOLE_LEVEL 8 /* Return number of unread characters in the log buffer */ #define SYSLOG_ACTION_SIZE_UNREAD 9 /* Return size of the log buffer */ #define SYSLOG_ACTION_SIZE_BUFFER 10 #define SYSLOG_FROM_READER 0 #define SYSLOG_FROM_PROC 1 int do_syslog(int type, char __user *buf, int count, int source); #endif /* _LINUX_SYSLOG_H */在实现上面的 syslog/klogctl 层之后,kmsg proc 文件系统成为一个 I/O 通道(在 ./linux/fs/proc/kmsg.c 中实现的),它提供了从内核缓冲区读取日志消息的二进制接口。这个读取操作通常是由一个守护程序(klogd 或 rsyslogd)实现的,它会处理这些消息,然后将它们传递给 rsyslog,以便(基于它的配置)转发到正确的日志文件中。文件 /proc/kmsg 实现了少数等同于内部 do_syslog 的文件操作。在内部,open 调用与 SYSLOG_ACTION_OPEN 有关,而 SYSLOG_ACTION_CLOSE 则与 release 有关(每一个调用都实现为一个 No Operation Performed [NOP])。这个轮循操作会等待文件活动的完成,然后才调用 SYSLOG_ACTION_SIZE_UNREAD 确定可以读取的字符数。最后,read 操作会被映射到 SYSLOG_ACTION_READ,以处理可用的日志消息。注意,用户是不会用到 /proc/kmsg 文件的:守护程序用它来获取日志消息,并将它们转发到 /var 空间内必要的日志文件中。用户空间应用程序用户空间提供了许多读取和管理内核日志的访问方法。我们开始先介绍较底层的接口(如 /proc 文件系统配置元素),然后再介绍更高层的应用程序。/proc 文件系统不仅提供了一个访问日志消息(kmsg)的二进制接口。它还有许多与上面讨论的 syslog/klogctl 相关或无关的配置元素。清单 1 显示了这些参数。清单 1. /proc 中的 printk 配置参数mtj@ubuntu:~$ cat /proc/sys/kernel/printk 4 4 1 7 mtj@ubuntu:~$ cat /proc/sys/kernel/printk_delay 0 mtj@ubuntu:~$ cat /proc/sys/kernel/printk_ratelimit 5 mtj@ubuntu:~$ cat /proc/sys/kernel/printk_ratelimit_burst 10在清单 1 中,第一项定义了 printk API 当前使用的日志级别。这些日志级别表示了控制台的日志级别、默认消息日志级别、最小控制台日志级别和默认控制台日志级别。printk_delay 值表示的是 printk 消息之间的延迟毫秒数(用于提高某些场景的可读性)。注意,这里它的值为 0,而它是不可以通过 /proc 设置的。printk_ratelimit 定义了消息之间允许的最小时间间隔(当前定义为每 5 秒内的某个内核消息数)。消息数量是由 printk_ratelimit_burst 定义的(当前定义为 10)。如果您拥有一个非正式内核而又使用有带宽限制的控制台设备(如通过串口), 那么这非常有用。注意,在内核中,速度限制是由调用者控制的,而不是在 printk 中实现的。如果一个 printk 用户要求进行速度限制,那么该用户就需要调用 printk_ratelimit 函数。dmesg 命令也可用于打印和控制内核环缓冲区。这个命令使用 klogctl 系统调用来读取内核环缓冲区,并将它转发到标准输出(stdout)。这个命令也可以用来清除内核环缓冲区(使用 -c 选项),设置控制台日志级别(-n 选项),以及定义用于读取内核日志消息的缓冲区大小(-s 选项)。注意,如果没有指定缓冲区大小,那么 dmesg 会使用 klogctl 的 SYSLOG_ACTION_SIZE_BUFFER 操作确定缓冲区大小。最后,所有日志应用程序都是基于一个标准化日志框架 syslog,主流操作系统(包括 Linux® 和 Berkeley Software Distribution [BSD])都实现了这个框架。syslog 使用自身的协议实现在不同传输协议的事件通知消息传输(将组件分成发起者、中继者和收集者)。在许多情况中,所有这三种组件都在一个主机上实现。除了 syslog 的许多有意思的特性,它还规定了日志信息是如何收集、过滤和存储的。syslog 已经经过了许多的变化和发展。您可能听过 syslog、klog 或 sysklogd。最新版本的 Ubuntu 使用的是名为 rsyslog(基于原先的 syslog)的新版本 syslog,它指的是可靠的和扩展的 syslogd。syslogd 守护程序通过它的配置文件 /etc/rsyslog.conf 来理解 /proc 文件系统的 kmsg 接口,并使用这些接口获取内核日志消息。注意,在内部,所有日志级别都是通过 /proc/kmsg 写入的,这样所传输的日志级别就不是由内核决定的,而是由 rsyslog 本身决定的。然后这些内核日志消息会存储在 /var/log/kern.log(及其他配置的文件)。在 /var/log 中有许多的日志文件,包括一般消息和系统相调用(/var/log/messages)、系统启动日志(/var/log/boot.log)、认证日志(/var/log/auth.log)等等。虽然您可以检查这些日志,但是您也可以使用它们进行自动审计和检查。有许多日志文件分析器可以用于故障修复, 或者满足安全规范要求,以及自动地使用诸如模式识别或相关性分析(甚至是跨系统的)来发现问题。结束语本文简单地介绍了内核日志和一些应用程序—包括在内核中创建内核日志消息,在内核的环缓冲区存储消息,使用 syslog/klogctl 或 /proc/kmsg 实现到用户空间的消息传输,通过 rsyslog 日志框架实现转发,以及它在 /var/log 子树的最终测试位置。Linux 提供了(包括内核及外部空间的)丰富且灵活的日志框架。
内核日志:API及实现 [TOC]内核版本:Linux5.4.0本文首先通过介绍用于配置和收集日志信息的应用程序接口(API)来说明了内核的日志(见图 1 关于总结框架和组件的示意图)。然后,本文介绍了日志数据从内核到用户空间的移动过程。最后,本文还介绍了基于内核的日志数据的目标:用户空间中使用 rsyslog 进行日志管理。内核API内核的日志是通过 printk 函数实现的,它与用户空间对应函数 printf(按格式打印)具有相似的作用。printf 命令在编程语言中已存在很长时间,最近出现是在 C 语言中,但是最早出现可以追溯到 50 年代和 60 年代的 Fortran(PRINT 和 FORMAT 语句)、BCPL(writf 函数;BCPL 是 C 的前身)和 ALGOL 68 语言(printf 和 putf)。在内核中,printk(打印内核)可以使用与 printf 函数几乎一样的格式将将格式化消息写入到缓冲区。您可以在 ./linux/include/linux/kernel.h(及其实现 ./linux/kernel/printk.c)中看到 printk 的格式:int printk( const char * fmt, ... );这个格式表示的是一个用于定义文本和格式的字符串(类似于 printf),它同时带有一组可变个数参数(由省略号表示 [...])。内核配置与错误通过 printk 实现的日志是通过内核配置选项 CONFIG_PRINTK 激活的。虽然 CONFIG_PRINTK 一般都是激活的,但是不包含这个选项的系统对内核的调用会返回一个 ENOSYS 错误返回值。在使用 printk 时,您首先会发现的不同点更多是关于协议,而不是功能的。这个特性使用了 C 语言的一种模糊方面来简化消息级别和优先级的规范。内核允许每一个消息根据日志级别(定义不同消息重要必的八种级别之一)来分类。这些级别可以用来判断系统是否不可用(紧急消息)、是否发现严重状况(严重消息)或者是否为简单报告消息。 这个内核代码直接将日志级别定义消息的第一个参数,下面这个例子说明的就是严重消息的定义:printk( KERN_CRIT "Error code %08x.\n", val );注意,第一个参数并不一个真正的参数,因为其中没有用于分隔级别(KERN_CRIT)和格式字符的逗号(,)。KERN_CRIT 本身只是一个普通的字符串(事实上,它表示的是字符串 "2";表 1 列出了完整的日志级别清单)。作为预处理程序的一部分,C 会自动地使用一个名为 字符串串联 的功能将这两个字符串组合在一起。组合的结果是将日志级别和用户指定的格式字符串包含在一个字符串中。注意,如果调用者未将日志级别提供给 printk,那么系统就会使用默认值 KERN_WARNING(表示只有 KERN_WARNING 级别以上的日志消息会被记录。)在头文件include/linux/kernel_levels.h里面,定义了日志级别和使用方法:// 位置:include/linux/kernel_levels.h #define KERN_SOH "\001" /* ASCII Start Of Header */ #define KERN_SOH_ASCII '\001' #define KERN_EMERG KERN_SOH "0" /* system is unusable */ #define KERN_ALERT KERN_SOH "1" /* action must be taken immediately */ #define KERN_CRIT KERN_SOH "2" /* critical conditions */ #define KERN_ERR KERN_SOH "3" /* error conditions */ #define KERN_WARNING KERN_SOH "4" /* warning conditions */ #define KERN_NOTICE KERN_SOH "5" /* normal but significant condition */ #define KERN_INFO KERN_SOH "6" /* informational */ #define KERN_DEBUG KERN_SOH "7" /* debug-level messages */ #define KERN_DEFAULT KERN_SOH "d" /* the default kernel loglevel */printk可以在内核的任意上下文中调用。这个调用从 ./linux/kernel/printk.c 中的 printk 函数开始,它会在使用 va_start 解析可变长度参数之后调用 vprintk(在同一个源文件)。printk函数的实现如下:asmlinkage __visible int printk(const char *fmt, ...) { va_list args; // 可变参数 int r; va_start(args, fmt); r = vprintk_func(fmt, args); va_end(args); return r; } EXPORT_SYMBOL(printk);其中vprintk_func()函数定以如下:__printf(1, 0) int vprintk_func(const char *fmt, va_list args) { /* * Try to use the main logbuf even in NMI. But avoid calling console * drivers that might have their own locks. */ if ((this_cpu_read(printk_context) & PRINTK_NMI_DIRECT_CONTEXT_MASK) && raw_spin_trylock(&logbuf_lock)) { int len; len = vprintk_store(0, LOGLEVEL_DEFAULT, NULL, 0, fmt, args); raw_spin_unlock(&logbuf_lock); defer_console_output(); return len; } /* Use extra buffer in NMI when logbuf_lock is taken or in safe mode. */ if (this_cpu_read(printk_context) & PRINTK_NMI_CONTEXT_MASK) return vprintk_nmi(fmt, args); /* Use extra buffer to prevent a recursion deadlock in safe mode. */ if (this_cpu_read(printk_context) & PRINTK_SAFE_CONTEXT_MASK) return vprintk_safe(fmt, args); /* No obstacles. */ return vprintk_default(fmt, args); }vprintk 函数执行了许多管理级检查(递归检查),然后获取日志缓冲区的锁(\_\_log_buf)。接下来,它会对输入的字符串进行日志级别检查; 如果发现日志级别信息,那么对应的日志级别就会被设置。最后,vprintk 会获取当前时间(使用函数 cpu_clock)并使用 sprintf(不是标准库版本,而是在 ./linux/lib/vsprintf.c 中实现的内部内核版本)将它转换成一个字符串。这个字符串会被传递给 printk,然后它会被一个管理缓冲边界(emit_log_char)的特殊函数复制到内核日志缓冲区中。这个函数最后将获取和释放执行控制台信号,并将下一条日志消息发送到控制台(在 release_console_sem 中执行)。内核缓冲缓冲区的大小初始值为 4KB,但是最新的内核大小已经升级到 16KB(在不同的体系架构上,这个值最高可以达到 1MB)。日志辅助函数内核也提供了一些日志辅助函数,它们可以简化日志函数的使用。每一个日志级别都有一个对应的函数,它会扩展为 printk 函数的一个宏。例如,如果要使用 printk 处理 KERN_EMERG 日志级别时,您可以直接使用 pr_emerg。所有宏都已列在 ./linux/include/linux/kernel.h 文件中。至此,您已经了解用于将日志消息插入到内核环缓冲区的 API。现在,让我们讨论一下用于将数据从内核移动到用户空间的方法。内核日志与接口多用途的 syslog 系统调用提供了内核的日志缓冲区访问方法。这个调用执行了很多个操作,所有操作都可以在用户空间执行,但是只有一个操作可以被非 root 用户执行。syslog 系统调用的原型定义位于 ./linux/include/linux/syslog.h;而它的实现位于 ./linux/kernel/printk.c。syslog 调用是作为内核日志消息环缓冲区的输入/输出(I/O)和控制接口。通过 syslog 调用,应用程序可以读取日志消息(部分、整体或者只读取新消息), 以及控制环缓冲区的行为(清除内容、设置日志的消息级别、启用或禁用控制台等等)。图 2 用图形说明了使用所讨论的主要组件进行日志记录的过程。syslog 调用(在内核中调用 ./linux/kernel/printk.c 的 do_syslog)是一个相对较小的函数,它能够读取和控制内核环缓冲区。注意在 glibc 2.0 中,由于词汇 syslog 使用过于广泛,这个函数的名称被修改成 klogctl,它指的是各种调用和应用程序。syslog 和 klogctl(在用户空间中)的原型函数定义为:int syslog( int type, char *bufp, int len ); int klogctl( int type, char *bufp, int len );type 参数是用于传递所执行的命令,它指定了可选的缓冲区长度。有一些命令(如清除环缓冲)是忽略 bufp 和 len 这两个参数的。虽然前面两个命令类型不会对内核进行任何操作,但是其余命令则是用于读取日志消息或控制日志。其中有三个命令是用于读取日志消息的。SYSLOG_ACTION_READ 用于阻塞操作,直至日志消息到达后才释放该操作,然后将它们返回到所提供的缓冲区。这个命令会处理这些消息(旧的消息将不会出现在这个命令的后续调用中。)SYSLOG_ACTION_READ_ALL 命令会从日志读取最后 n 个字符(而 n 是在传递给 klogctl 的参数 'len' 中定义的)。SYSLOG_ACTION_READ_CLEAR 命令会先执行 SYSLOG_ACTION_READ_ALL 操作,然后执行 SYSLOG_ACTION_CLEAR 命令(清除环缓冲区)。SYSLOG_ACTION_CONSOLE ON 和 OFF 可以将日志级别设置为激活或禁用日志消息输出到控制台,而 SYSLOG_CONSOLE_LEVEL 则允许调用者定义控制台所接受的日志消息级别。最后,SYSLOG_ACTION_SIZE_BUFFER 是用于返回内核环缓冲区大小,而 SYSLOG_ACTION_SIZE_UNREAD 则返回当前内核环缓冲区可读取的字符数。表 2 显示了 SYSLOG 命令的完整清单。使用 syslog/klogctl 系统调用实现的命令:#ifndef _LINUX_SYSLOG_H #define _LINUX_SYSLOG_H /* Close the log. Currently a NOP. */ #define SYSLOG_ACTION_CLOSE 0 /* Open the log. Currently a NOP. */ #define SYSLOG_ACTION_OPEN 1 /* Read from the log. */ #define SYSLOG_ACTION_READ 2 /* Read all messages remaining in the ring buffer. */ #define SYSLOG_ACTION_READ_ALL 3 /* Read and clear all messages remaining in the ring buffer */ #define SYSLOG_ACTION_READ_CLEAR 4 /* Clear ring buffer. */ #define SYSLOG_ACTION_CLEAR 5 /* Disable printk's to console */ #define SYSLOG_ACTION_CONSOLE_OFF 6 /* Enable printk's to console */ #define SYSLOG_ACTION_CONSOLE_ON 7 /* Set level of messages printed to console */ #define SYSLOG_ACTION_CONSOLE_LEVEL 8 /* Return number of unread characters in the log buffer */ #define SYSLOG_ACTION_SIZE_UNREAD 9 /* Return size of the log buffer */ #define SYSLOG_ACTION_SIZE_BUFFER 10 #define SYSLOG_FROM_READER 0 #define SYSLOG_FROM_PROC 1 int do_syslog(int type, char __user *buf, int count, int source); #endif /* _LINUX_SYSLOG_H */在实现上面的 syslog/klogctl 层之后,kmsg proc 文件系统成为一个 I/O 通道(在 ./linux/fs/proc/kmsg.c 中实现的),它提供了从内核缓冲区读取日志消息的二进制接口。这个读取操作通常是由一个守护程序(klogd 或 rsyslogd)实现的,它会处理这些消息,然后将它们传递给 rsyslog,以便(基于它的配置)转发到正确的日志文件中。文件 /proc/kmsg 实现了少数等同于内部 do_syslog 的文件操作。在内部,open 调用与 SYSLOG_ACTION_OPEN 有关,而 SYSLOG_ACTION_CLOSE 则与 release 有关(每一个调用都实现为一个 No Operation Performed [NOP])。这个轮循操作会等待文件活动的完成,然后才调用 SYSLOG_ACTION_SIZE_UNREAD 确定可以读取的字符数。最后,read 操作会被映射到 SYSLOG_ACTION_READ,以处理可用的日志消息。注意,用户是不会用到 /proc/kmsg 文件的:守护程序用它来获取日志消息,并将它们转发到 /var 空间内必要的日志文件中。用户空间应用程序用户空间提供了许多读取和管理内核日志的访问方法。我们开始先介绍较底层的接口(如 /proc 文件系统配置元素),然后再介绍更高层的应用程序。/proc 文件系统不仅提供了一个访问日志消息(kmsg)的二进制接口。它还有许多与上面讨论的 syslog/klogctl 相关或无关的配置元素。清单 1 显示了这些参数。清单 1. /proc 中的 printk 配置参数mtj@ubuntu:~$ cat /proc/sys/kernel/printk 4 4 1 7 mtj@ubuntu:~$ cat /proc/sys/kernel/printk_delay 0 mtj@ubuntu:~$ cat /proc/sys/kernel/printk_ratelimit 5 mtj@ubuntu:~$ cat /proc/sys/kernel/printk_ratelimit_burst 10在清单 1 中,第一项定义了 printk API 当前使用的日志级别。这些日志级别表示了控制台的日志级别、默认消息日志级别、最小控制台日志级别和默认控制台日志级别。printk_delay 值表示的是 printk 消息之间的延迟毫秒数(用于提高某些场景的可读性)。注意,这里它的值为 0,而它是不可以通过 /proc 设置的。printk_ratelimit 定义了消息之间允许的最小时间间隔(当前定义为每 5 秒内的某个内核消息数)。消息数量是由 printk_ratelimit_burst 定义的(当前定义为 10)。如果您拥有一个非正式内核而又使用有带宽限制的控制台设备(如通过串口), 那么这非常有用。注意,在内核中,速度限制是由调用者控制的,而不是在 printk 中实现的。如果一个 printk 用户要求进行速度限制,那么该用户就需要调用 printk_ratelimit 函数。dmesg 命令也可用于打印和控制内核环缓冲区。这个命令使用 klogctl 系统调用来读取内核环缓冲区,并将它转发到标准输出(stdout)。这个命令也可以用来清除内核环缓冲区(使用 -c 选项),设置控制台日志级别(-n 选项),以及定义用于读取内核日志消息的缓冲区大小(-s 选项)。注意,如果没有指定缓冲区大小,那么 dmesg 会使用 klogctl 的 SYSLOG_ACTION_SIZE_BUFFER 操作确定缓冲区大小。最后,所有日志应用程序都是基于一个标准化日志框架 syslog,主流操作系统(包括 Linux® 和 Berkeley Software Distribution [BSD])都实现了这个框架。syslog 使用自身的协议实现在不同传输协议的事件通知消息传输(将组件分成发起者、中继者和收集者)。在许多情况中,所有这三种组件都在一个主机上实现。除了 syslog 的许多有意思的特性,它还规定了日志信息是如何收集、过滤和存储的。syslog 已经经过了许多的变化和发展。您可能听过 syslog、klog 或 sysklogd。最新版本的 Ubuntu 使用的是名为 rsyslog(基于原先的 syslog)的新版本 syslog,它指的是可靠的和扩展的 syslogd。syslogd 守护程序通过它的配置文件 /etc/rsyslog.conf 来理解 /proc 文件系统的 kmsg 接口,并使用这些接口获取内核日志消息。注意,在内部,所有日志级别都是通过 /proc/kmsg 写入的,这样所传输的日志级别就不是由内核决定的,而是由 rsyslog 本身决定的。然后这些内核日志消息会存储在 /var/log/kern.log(及其他配置的文件)。在 /var/log 中有许多的日志文件,包括一般消息和系统相调用(/var/log/messages)、系统启动日志(/var/log/boot.log)、认证日志(/var/log/auth.log)等等。虽然您可以检查这些日志,但是您也可以使用它们进行自动审计和检查。有许多日志文件分析器可以用于故障修复, 或者满足安全规范要求,以及自动地使用诸如模式识别或相关性分析(甚至是跨系统的)来发现问题。结束语本文简单地介绍了内核日志和一些应用程序—包括在内核中创建内核日志消息,在内核的环缓冲区存储消息,使用 syslog/klogctl 或 /proc/kmsg 实现到用户空间的消息传输,通过 rsyslog 日志框架实现转发,以及它在 /var/log 子树的最终测试位置。Linux 提供了(包括内核及外部空间的)丰富且灵活的日志框架。 -
测试插入b站视频 .aspect-ratio {position: relative;width: 100%;height: 0;padding-bottom: 75%;}.aspect-ratio iframe {position: absolute;width: 100%;height: 100%;left: 0;top: 0;} test 参考: https://blog.csdn.net/xinshou_caizhu/article/details/94028606?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param
-
在qemu上运行ARM 代码仓库在https://github.com/ADTXL/qemu_kernel喜欢的话可以点下star1. 简介学习kenel,使用qemu搭建环境2. 使用说明2.1 编译安装qemu参考qemu/readme.md2.2 安装toolchain本来打算把toolchain也直接上传的,arm64的toolchain有些文件大于100M,不太好直接上传,只上传了arm32的toolchain.如果对版本没有要求可以直接使用命令安装,# 32 bit sudo apt-get install gcc-arm-linux-gnueabihf # 64 bit sudo apt install gcc-aarch64-linux-gnu2.3 编译以编译和运行arm64为例2.3.1 修改路径运行脚本时需要修改脚本run_qemu中和路径"qemuBinPath"和"KernelRootPath"为真实的存在路径2.3.2 编译有些包没有的可能需要安装下,还有些缺少的根据编译报错安装即可,下面是我编译时需要的包sudo apt install bison sudo apt install flex sudo apt install openssl sudo apt install libssl-dev sudo apt install bc然后编译cd buildroot/linux/qemu/arm make -j62.3.3 运行使用如下命令cd buildroot/linux/qemu/arm ./run_qemu.sh如下所示:user@b10fa2dc8f66:~/txl/project/qemu_kernel/buildroot/linux/qemu/arm$ ./run_qemu.sh run qemu without external filesystem mke2fs 1.44.1 (24-Mar-2018) Creating regular file /home/user/txl/project/qemu_kernel/work/linux-qemu-arm-4_19/image/rootfs.ext4 Creating filesystem with 512000 1k blocks and 128016 inodes Filesystem UUID: 61e2e1d6-dbfb-4068-a749-eba9e5bbfe54 Superblock backups stored on blocks: 8193, 24577, 40961, 57345, 73729, 204801, 221185, 401409 Allocating group tables: done Writing inode tables: done Creating journal (8192 blocks): done Copying files into the device: done Writing superblocks and filesystem accounting information: ...... [ 0.794850] devtmpfs: mounted [ 0.969362] Freeing unused kernel memory: 768K [ 0.971016] Run /sbin/init as init process mount: mounting tmpfs on /tmp failed: Invalid argument mount: mounting sdcardfs on /sdcard failed: No such device [ 1.102253] EXT4-fs (vda): re-mounted. Opts: (null) Processing /etc/profile... Done / # ls bin home lost+found root sys usr dev lib mnt sbin system var etc linuxrc proc sdcard tmp 如果想退出,按Ctrl +a,然后再按x即可。3. 目录结构说明TODO
-
uboot的介绍 目录::stuck_out_tongue_winking_eye:[TOC]1. uboot是干嘛的uboot 属于bootloader的一种,是用来引导启动内核的,它的最终目的就是,从flash中读出内核,放到内存中,启动内核所以,由上面描述的,就知道,UBOOT需要具有读写flash的能力。2. uboot怎么启动内核uboot刚开始被放到flash中,板子上电后,会自动把其中的一部分代码拷到内存中执行,这部分代码负责把剩余的uboot代码拷到内存中,然后uboot代码再把kernel部分代码也拷到内存中,并且启动,内核启动后,挂着根文件系统,执行应用程序。参考:https://blog.csdn.net/yilongdashi/article/details/87968572
-
动态内存分配 目录:[TOC]1.malloc和free函数原型如下,在头文件stdlib.h中声明:void *malloc(size_t size); void free(void *pointer);malloc的参数是需要分配的内存字节数。如果内存池中的可用内存可以满足这个需求,malloc就返回一个指向被分配的内存块起始位置的指针。malloc分配的是一块连续的内存,并且不对这块内存进行任何的初始化。如果操作系统无法向malloc提供更多的内存,malloc就返回一个NULL指针。因此,对每个从malloc返回的指针都进行检查,确保它并非NULL是非常重要的。free的参数必须要么是NULL,要么是一个先前从malloc、calloc或realloc返回的值。向free传递一个NULL参数不会产生任何效果。malloc返回一个类型为void*的指针,一个void*类型的指针可以转换成其它任何类型的指针2.calloc和realloccalloc和realloc的函数原型如下所示:void *calloc(size_t num_elements, size_t element_size); void realloc(void *ptr, size_t new_size);malloc和calloc之间的主要区别是calloc在返回指向内存的指针之前把它初始化为0。calloc和malloc之间另一个较小的区别是它们请求内存数量的方式不同。calloc的参数包括所需元素的数量和每个元素的字节数。根据这些值,它能够计算出总共需要分配的内存。realloc函数用于修改一个原先已经分配的内存块的大小。使用这个函数,可以使一块内存扩大或缩小。如果它用于扩大一个内存块,那么这块内存原先的内容依然保留,新增加的内存添加到原先内存块的后面,新内存并未以任何方法进行初始化。如果它用于缩小内存块,该内存块尾部的部分内存便被拿掉,剩余部分内存的原先内容依然保留。如果原先的内存块无法改变大小,realloc将分配另一块正确大小的内存,并把原先那块内存的内容复制到新块上。因此,在使用realloc之后,你就不能再使用指向旧内存的指针,而是应该用realloc所返回的新指针。3. 常见的动态内存错误在使用动态内存分配的程序中,常常会出现许多错误。这些错误包括对NULL指针进行解引用操作、对分配的内存进行操作时越过边界、释放并非动态分配的内存、试图释放一块动态分配的内存以及一块动态内存被释放之后被继续使用。动态内存分配最常见的错误就是忘记检查所请求的内存是否成功分配// 记得对分配的内存进行检查 if (new_mem == NULL) printf( "Out of memory" ); exit(1);动态内存分配的第二大错误来源是操作内存时超出了分配内存的边界在malloc和free的有些实现中,它们以链表的形式维护可用的内存池。对分配的内存之外的区域进行访问可能破坏这个链表,这有可能产生异常,从而终止程序。
-
gcc和objdump 1. gcc-ansi 关闭 gnu c中与ansi c不兼容的特性,激活ansi c的专有特性 ( 包括禁止一些 asm inline typeof 关键字 , 以及 UNIX,vax 等预处理宏-lxx 表示动态加载libxx.so库-Lxx 表示增加目录xx,让编译器可以在xx下寻找库文件-Ixx 表示增加目录xx,让编译器可以在xx下寻找头文件优化选项-shared 生成共享目标文件。通常用在建立共享库时-Wall 生成所有警告信息。一下是具体的选项,可以单独使用简单的GCC语法:如果你只有一个文件(或者只有几个文件),那么就可以不写Makefile文件(当然有Makefile更加方便),用gcc直接编译就行了。在这里我们只介绍几个我经常用的几个参数,第一是 “-o”,它后面的参数表示要输出的目标文件,再一个是 “-c”,表示仅编译(Compile),不链接(Make),如果没有”-c”参数,那么就表示链接,如下面的几个命令:gcc –c test.c,表示只编译test.c文件,成功时输出目标文件test.ogcc –c test.c –o test.o ,与上一条命令完全相同gcc –o test test.o,将test.o连接成可执行的二进制文件testgcc –o test test.c,将test.c编译并连接成可执行的二进制文件testgcc test.c –o test,与上一条命令相同gcc –c test1.c,只编译test1.c,成功时输出目标文件test1.ogcc –c test2.c,只编译test2.c,成功时输出目标文件test2.ogcc –o test test1.o test2.o,将test1.o和test2.o连接为可执行的二进制文件testgcc –c test test1.c test2.c,将test1.o和test2.o编译并连接为可执行的二进制文件test注:如果你想编译cpp文件,那么请用g++,否则会有类似如下莫名其妙的错误:cc3r3i2U.o(.eh_frame+0x12): undefined reference to `__gxx_personality_v0’......还有一个参数是”-l”参数,与之紧紧相连的是表示连接时所要的链接库,比如多线程,如果你使用了pthread_create函数,那么你就应该在编译语句的最后加上”-lpthread”,”-l”表示连接,”pthread”表示要连接的库,注意他们在这里要连在一起写,还有比如你使用了光标库curses,那么呢就应该在后面加上”-lcurses”,比如下面的写法:gcc –o test test1.o test2.o –lpthread –lcurses例如: 在ubuntu 环境下编译基于course库函数的程序时,如果不带 -lncurses时,会出现screen1.c:(.text+0x12):对‘initscr’未定义的引用screen1.c:(.text+0x24):对‘wmove’未定义的引用screen1.c:(.text+0x39):对‘printw’未定义的引用screen1.c:(.text+0x4a):对‘wrefresh’未定义的引用screen1.c:(.text+0x5f):对‘endwin’未定义的引用需使用 gcc -o screen1 screen1.c -lncurses2. objdumpgcc命令之 objdump ---------------objdump是用查看目标文件或者可执行的目标文件的构成的GCC工具----------以下3条命令足够那些喜欢探索目标文件与源代码之间的丝丝的关系的朋友。objdump -x obj 以某种分类信息的形式把目标文件的数据组织(被分为几大块)输出 <可查到该文件的所有动态库> objdump -t obj 输出目标文件的符号表()objdump -h obj 输出目标文件的所有段概括()objdump -j .text/.data -S obj 输出指定段的信息,大概就是反汇编源代码把objdump -S obj C语言与汇编语言同时显示 以下为网上摘录文章。关于nm -s的显示请自己man nm查看objdump命令的man手册objdump - 显示二进制文件信息objdump [-a] [-b bfdname | --target=bfdname] [-C] [--debugging] [-d] [-D] [--disassemble-zeroes] [-EB|-EL|--endian={big|little}] [-f] [-h] [-i|--info] [-j section | --section=section] [-l] [-m machine ] [--prefix-addresses] [-r] [-R] [-s|--full-contents] [-S|--source] [--[no-]show-raw-insn] [--stabs] [-t] [-T] [-x] [--start-address=address] [--stop-address=address] [--adjust-vma=offset] [--version] [--help] objfile... --archive-headers-a 显示档案库的成员信息,与 ar tv 类似objdump -a libpcap.a 和 ar -tv libpcap.a 显示结果比较比较 显然这个选项没有什么意思。--adjust-vma=offsetWhen dumping information, first add offset to all the section addresses. This is useful if the sec- tion addresses do not correspond to the symbol table, which can happen when putting sections at particular addresses when using a format which can not represent section addresses, such as a.out.-b bfdname--target=bfdname指定目标码格式。这不是必须的,objdump能自动识别许多格式, 比如:objdump -b oasys -m vax -h fu.o 显示fu.o的头部摘要信息,明确指出该文件是Vax系统下用Oasys 编译器生成的目标文件。objdump -i将给出这里可以指定的 目标码格式列表--demangle-C 将底层的符号名解码成用户级名字,除了去掉所有开头 的下划线之外,还使得C++函数名以可理解的方式显示出来。--debugging显示调试信息。企图解析保存在文件中的调试信息并以C语言 的语法显示出来。仅仅支持某些类型的调试信息。--disassemble-d 反汇编那些应该还有指令机器码的section--disassemble-all-D 与 -d 类似,但反汇编所有section--prefix-addresses反汇编的时候,显示每一行的完整地址。这是一种比较老的反汇编格式。 显示效果并不理想,但可能会用到其中的某些显示,自己可以对比。--disassemble-zeroes一般反汇编输出将省略大块的零,该选项使得这些零块也被反汇编。-EB-EL--endian={big|little}这个选项将影响反汇编出来的指令。 little-endian就是我们当年在dos下玩汇编的时候常说的高位在高地址, x86都是这种。 --file-headers-f 显示objfile中每个文件的整体头部摘要信息。--section-headers--headers-h 显示目标文件各个section的头部摘要信息。--help 简短的帮助信息。--info-i 显示对于 -b 或者 -m 选项可用的架构和目标格式列表。--section=name-j name 仅仅显示指定section的信息--line-numbers-l 用文件名和行号标注相应的目标代码,仅仅和-d、-D或者-r一起使用 使用-ld和使用-d的区别不是很大,在源码级调试的时候有用,要求 编译时使用了-g之类的调试编译选项。--architecture=machine-m machine指定反汇编目标文件时使用的架构,当待反汇编文件本身没有描述 架构信息的时候(比如S-records),这个选项很有用。可以用-i选项 列出这里能够指定的架构 --reloc-r 显示文件的重定位入口。如果和-d或者-D一起使用,重定位部分以反汇 编后的格式显示出来。--dynamic-reloc-R 显示文件的动态重定位入口,仅仅对于动态目标文件有意义,比如某些 共享库。--full-contents-s 显示指定section的完整内容。objdump --section=.text -s inet.o | more --source-S 尽可能反汇编出源代码,尤其当编译的时候指定了-g这种调试参数时, 效果比较明显。隐含了-d参数。--show-raw-insn反汇编的时候,显示每条汇编指令对应的机器码,除非指定了 --prefix-addresses,这将是缺省选项。 --no-show-raw-insn反汇编时,不显示汇编指令的机器码,这是指定 --prefix-addresses 选项时的缺省设置。 --stabsDisplay the contents of the .stab, .stab.index, and .stab.excl sections from an ELF file. This is only useful on systems (such as Solaris 2.0) in which .stab debugging symbol-table entries are carried in an ELF section. In most other file formats, debug- ging symbol-table entries are interleaved with linkage symbols, and are visible in the --syms output. --start-address=address从指定地址开始显示数据,该选项影响-d、-r和-s选项的输出。 --stop-address=address显示数据直到指定地址为止,该选项影响-d、-r和-s选项的输出。 --syms-t 显示文件的符号表入口。类似于nm -s提供的信息--dynamic-syms-T 显示文件的动态符号表入口,仅仅对动态目标文件有意义,比如某些 共享库。它显示的信息类似于 nm -D|--dynamic 显示的信息。--version 版本信息objdump --version --all-headers-x 显示所有可用的头信息,包括符号表、重定位入口。-x 等价于 -a -f -h -r -t 同时指定。objdump -x inet.o 参看 nm(1)★ objdump应用举例(待增加)/*g++ -g -Wstrict-prototypes -Wall -Wunused -o objtest objtest.c*/includeincludeint main ( int argc, char * argv[] ){execl( "/bin/sh", "/bin/sh", "-i", 0 ); return 0;}g++ -g -Wstrict-prototypes -Wall -Wunused -o objtest objtest.cobjdump -j .text -Sl objtest | more/main(查找)08048750:main():/home/scz/src/objtest.c:7*/includeincludeint main ( int argc, char * argv[] ){8048750: 55 pushl %ebp8048751: 89 e5 movl %esp,%ebp/home/scz/src/objtest.c:8 execl( "/bin/sh", "/bin/sh", "-i", 0 );8048753: 6a 00 pushl $0x08048755: 68 d0 87 04 08 pushl $0x80487d0804875a: 68 d3 87 04 08 pushl $0x80487d3804875f: 68 d3 87 04 08 pushl $0x80487d38048764: e8 db fe ff ff call 8048644 <_init+0x40>8048769: 83 c4 10 addl $0x10,%esp/home/scz/src/objtest.c:9 return 0;804876c: 31 c0 xorl %eax,%eax804876e: eb 04 jmp 8048774 8048770: 31 c0 xorl %eax,%eax8048772: eb 00 jmp 8048774 /home/scz/src/objtest.c:10}8048774: c9 leave 8048775: c3 ret 8048776: 90 nop如果说上面还不够清楚,可以用下面的命令辅助一下:objdump -j .text -Sl objtest --prefix-addresses | moreobjdump -j .text -Dl objtest | more用以上不同的命令去试会得到惊喜!
-
目标文件格式 编译器编译源代码后生成的文件叫做目标文件。目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或有些地址还没有被调整。其实它本身就是按照可执行文件格式存储的,只是跟真正的可执行文件在结构上稍有不同。1.1 目标文件的格式Linux下的可执行文件格式是ELF(Executable Linkable Format)。ELF文件标准把系统中采用的ELF格式的文件分为四类,分别是:可重定位文件(Relocatable File)如Linux下的.o可执行文件(Executable File)共享目标文件(Shared Object File)如Linux下的.so核心转储文件(Core Dump File)当进程意外终止时,系统可以将该进程的地址空间的内容及终止时的一些其它信息转储到核心转储文件如Linux下的core dumpLinux下使用file命令可以查看相应的文件格式,file test.o1.2 目标文件时什么样的section(节)与segment(段)二者唯一的区别是在ELF的链接视图和装载视图的时候code section(代码段)存放编译后的机器指令,如".code"、".text"data section(数据段)存放编译后的全局变量和局部静态变量,如.data文件头ELF文件的开头是一个“文件头”,它描述了整个文件的文件属性,包括文件是否可执行、是静态链接还是动态链接及入口地址(如果是可执行文件)、目标硬件、目标操作系统等信息,文件头还包括一个段表。section table(段表)段表是一个描述文件中各个段的数组。段表描述了文件中各个段在文件中的偏移位置及段的属性等,从段表里面可以得到各个段的所有信息。.bss段未初始化的全局变量和局部静态变量一般放在.bss段。程序运行的时候这些变量确是要占内存空间的,并且可执行文件必须记录所有未初始化的全局变量和局部静态变量的大小总和。所以.bss段只是为位初始化的全局变量和局部静态变量预留位置而已,它并没有内容,所以在文件中也不占据空间。总体来说,程序源代码被编译以后主要分成两种段:程序指令和程序数据。代码段属于程序指令,而数据段和.bss段属于程序数据。1.3 一个实例:simple_section.osimple_section.c代码如下:/* * Linux: gcc -c simple-section.c */ int printf( const char* format, ... ); int global_int_var = 84; int global_uninit_var; void func1(int i) { printf( "%d\n", i); } int main(void) { static int static_var = 85; static int static_var2; int a = 1; int b; func1( static_var + static_var2 + a + b ); return a; }使用gcc编译文件(-c参数表示只编译不链接)gcc -c simple_section.c 使用objdump查看目标文件的结构和内容,Linux下还有一个工具readelf,是专门针对elf文件格式的解析器参数-h把各个段的信息打印出来,-x打印更多的信息objdump -h simple_section.o显示如下:user@user-HP-ProDesk-600-G5-MT:~/txl/code/c/simlesection$ objdump -h simple_section.o simple_section.o: 文件格式 elf64-x86-64 节: Idx Name Size VMA LMA File off Algn 0 .text 00000057 0000000000000000 0000000000000000 00000040 2**0 CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE 1 .data 00000008 0000000000000000 0000000000000000 00000098 2**2 CONTENTS, ALLOC, LOAD, DATA 2 .bss 00000004 0000000000000000 0000000000000000 000000a0 2**2 ALLOC 3 .rodata 00000004 0000000000000000 0000000000000000 000000a0 2**0 CONTENTS, ALLOC, LOAD, READONLY, DATA 4 .comment 0000002a 0000000000000000 0000000000000000 000000a4 2**0 CONTENTS, READONLY 5 .note.GNU-stack 00000000 0000000000000000 0000000000000000 000000ce 2**0 CONTENTS, READONLY 6 .eh_frame 00000058 0000000000000000 0000000000000000 000000d0 2**3 CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA 其中Size表示段的长度,File off表示段所在的位置,每个段的第二行CONTENTS, ALLOC等表示段的属性,“CONTENTS”表示段在文件中存在。使用size命令,可以用来查看ELF文件代码段、数据段和bss段的长度(dec表示3个段长度和的十进制,hex表示长度和的十六进制)user@user-HP-ProDesk-600-G5-MT:~/txl/code/c/simlesection$ size simple_section.o text data bss dec hex filename 179 8 4 191 bf simple_section.o objdump的“-s”参数可以将所有段的内容以十六进制的方式打印出来,“-d”参数可以将所有包含指令的段反汇编objdump -s -d simple_section.o显示内容如下:simple_section.o: 文件格式 elf64-x86-64 Contents of section .text: 0000 554889e5 4883ec10 897dfc8b 45fc89c6 UH..H....}..E... 0010 488d3d00 000000b8 00000000 e8000000 H.=............. 0020 0090c9c3 554889e5 4883ec10 c745f801 ....UH..H....E.. 0030 0000008b 15000000 008b0500 00000001 ................ 0040 c28b45f8 01c28b45 fc01d089 c7e80000 ..E....E........ 0050 00008b45 f8c9c3 ...E... Contents of section .data: 0000 54000000 55000000 T...U... Contents of section .rodata: 0000 25640a00 %d.. Contents of section .comment: 0000 00474343 3a202855 62756e74 7520372e .GCC: (Ubuntu 7. 0010 352e302d 33756275 6e747531 7e31382e 5.0-3ubuntu1~18. 0020 30342920 372e352e 3000 04) 7.5.0. Contents of section .eh_frame: 0000 14000000 00000000 017a5200 01781001 .........zR..x.. 0010 1b0c0708 90010000 1c000000 1c000000 ................ 0020 00000000 24000000 00410e10 8602430d ....$....A....C. 0030 065f0c07 08000000 1c000000 3c000000 ._..........<... 0040 00000000 33000000 00410e10 8602430d ....3....A....C. 0050 066e0c07 08000000 .n...... Disassembly of section .text: 0000000000000000 <func1>: 0: 55 push %rbp 1: 48 89 e5 mov %rsp,%rbp 4: 48 83 ec 10 sub $0x10,%rsp 8: 89 7d fc mov %edi,-0x4(%rbp) b: 8b 45 fc mov -0x4(%rbp),%eax e: 89 c6 mov %eax,%esi 10: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 17 <func1+0x17> 17: b8 00 00 00 00 mov $0x0,%eax 1c: e8 00 00 00 00 callq 21 <func1+0x21> 21: 90 nop 22: c9 leaveq 23: c3 retq 0000000000000024 <main>: 24: 55 push %rbp 25: 48 89 e5 mov %rsp,%rbp 28: 48 83 ec 10 sub $0x10,%rsp 2c: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%rbp) 33: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # 39 <main+0x15> 39: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 3f <main+0x1b> 3f: 01 c2 add %eax,%edx 41: 8b 45 f8 mov -0x8(%rbp),%eax 44: 01 c2 add %eax,%edx 46: 8b 45 fc mov -0x4(%rbp),%eax 49: 01 d0 add %edx,%eax 4b: 89 c7 mov %eax,%edi 4d: e8 00 00 00 00 callq 52 <main+0x2e> 52: 8b 45 f8 mov -0x8(%rbp),%eax 55: c9 leaveq 56: c3 retq 在.text段,最左面一列是偏移量,中间四列是十六进制内容,最右面一列是.text段的ASCII码形式。.data段保存的是那些已经初始化了的全局静态变量和局部静态变量。字符串常量"%d\n",它是一种只读数据,所以它被放到了“.rodata”段,我们可以从输出结果看到".rodata"这个段的4个字节刚好是这个字符串常量的ASCII字节序,最后以\0结尾。.bss段存放的是未初始化的全局变量和局部静态变量。还有一些其它的常用段如下:常用的段名说明.rodata跟.rodata一样.interp/lib64/ld-linux.so.2(动态链接器的路径,有入口函数,装载的时候启动).dynamic动态链接信息.symtab用于静态链接和调试(符号表保留在文件中,不加载进内存).dynsym用于动态链接(符号表会被加载进内存).init和.finit1 共享对象可能会持有这两个段,做为共享对象的入口和出口函数 2 c++中的全局对象,或者static对象的构造函数和析构函数.comment存放的是编译器版本信息.debug调试信息.plt和.got动态链接的跳转表和全局入口表1.4 ELF文件结构描述ELF目标文件格式的最前部是ELF文件头,它描述了整个文件的基本属性,比如ELF文件版本、目标机器型号、程序入口地址等。紧接着就是各个段。其中ELF文件中与段有关的重要结构就是段表,该表描述了ELF文件包含的所有段的信息,比如每个段的段名、段的长度、在文件中的偏移、读写权限及段的其他属性。1.4.1 文件头使用readelf命令来详细查看ELF文件,readelf -h simple_section.o输出如下:ELF 头: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 类别: ELF64 数据: 2 补码,小端序 (little endian) 版本: 1 (current) OS/ABI: UNIX - System V ABI 版本: 0 类型: REL (可重定位文件) 系统架构: Advanced Micro Devices X86-64 版本: 0x1 入口点地址: 0x0 程序头起点: 0 (bytes into file) Start of section headers: 1104 (bytes into file) 标志: 0x0 本头的大小: 64 (字节) 程序头大小: 0 (字节) Number of program headers: 0 节头大小: 64 (字节) 节头数量: 13 字符串表索引节头: 12 ELF魔数:最前面的16个字节刚好对应“Elf32_Ehdr”的e_ident这个成员。1.4.2 段表使用readelf工具来查看文件的段,它显示出来的结果才是真正的段表结构readelf -S simple_section.o输出如下:There are 13 section headers, starting at offset 0x450: 节头: [号] 名称 类型 地址 偏移量 大小 全体大小 旗标 链接 信息 对齐 [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] .text PROGBITS 0000000000000000 00000040 0000000000000057 0000000000000000 AX 0 0 1 [ 2] .rela.text RELA 0000000000000000 00000340 0000000000000078 0000000000000018 I 10 1 8 [ 3] .data PROGBITS 0000000000000000 00000098 0000000000000008 0000000000000000 WA 0 0 4 [ 4] .bss NOBITS 0000000000000000 000000a0 0000000000000004 0000000000000000 WA 0 0 4 [ 5] .rodata PROGBITS 0000000000000000 000000a0 0000000000000004 0000000000000000 A 0 0 1 [ 6] .comment PROGBITS 0000000000000000 000000a4 000000000000002a 0000000000000001 MS 0 0 1 [ 7] .note.GNU-stack PROGBITS 0000000000000000 000000ce 0000000000000000 0000000000000000 0 0 1 [ 8] .eh_frame PROGBITS 0000000000000000 000000d0 0000000000000058 0000000000000000 A 0 0 8 [ 9] .rela.eh_frame RELA 0000000000000000 000003b8 0000000000000030 0000000000000018 I 10 8 8 [10] .symtab SYMTAB 0000000000000000 00000128 0000000000000198 0000000000000018 11 11 8 [11] .strtab STRTAB 0000000000000000 000002c0 000000000000007c 0000000000000000 0 0 1 [12] .shstrtab STRTAB 0000000000000000 000003e8 0000000000000061 0000000000000000 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), I (info), L (link order), O (extra OS processing required), G (group), T (TLS), C (compressed), x (unknown), o (OS specific), E (exclude), l (large), p (processor specific) 1.4.3 重定位表.rela.text类型位RELA,是一个重定位表。链接器在处理目标文件时,需要对目标文件中某些部位进行重定位,即代码段和数据段中那些绝对地址的引用的位置。这些重定位信息都记录在重定位表里面。.rela.text段就是.text段的重定位表,因为.text段中至少有一个绝对地址的引用,那就是对printf函数的调用。而.data段则没有对绝对地址的引用,它只包含了几个常量,所以没有针对data段的重定位表。1.4.4 字符串表.strtab(string table): 字符串表,用来保存普通的字符串 .shstrtab(section header string table):用来保存段表中用到的字符串,最常见的就是段名
-
内核配置 1.内核源码编译过程1.遍历每个源码目录的(或配置指定的源码目录)Makefile2.每个目录的Makefile会根据Kconfig文件定制要编译的对象3.最后回到顶层目录的Makefile执行编译据此,我们可以得出各个文件的作用Kconfig--->(每个源码目录下)提供选项.config--->(源码顶层目录下)保存选择结果Makefile--->(每个源码目录下)根据.config中的内容来告知编译系统如何编译2. Kconfig基本语法2.1 单一选项总体原则:每一个config就是一个选项,最上面跟着控制句柄,下面则是对这个选项的配置,如选项名是什么,依赖什么,选中这个后同时会选择什么。config CPU_S5PC100 bool "选项名" select S5P_EXT_INT select SAMSUNG_DMADEV help Enable S5PC100 CPU supportconfig —> 选项CPU_S5PC100 —>句柄,可用于控制Makefile 选择编译方式bool —>选择可能:TRUE选中、FALSE不选 选中则编译,不选中则不编译。如果后面没有字符串名称,则表示其不会出现在选择软件列表中select —> 当前选项选中后则select后指定的选项自动被选择depends on ARM || BLACKFIN || MIPS || COLDFIREdepend on 依赖,后面的四个选择其中至少一个被选择,这个选项才能被选config DM9000 tristate "DM9000 support"tristate —> 选中并编译进内核、不选编译成模块2.2 选项为数字config ARM_DMA_IOMMU_ALIGNMENT int "Maximum PAGE_SIZE order of alignment for DMA IOMMU buffers" ---->该选项是一个整型值 range 4 9 ---->该选项的范围值 default 8 ---->该选项的默认值 help DMA mapping framework by default aligns all buffers to the smallest ...这里的defult其实也可以用在bool中config STACKTRACE_SUPPORT bool --->该选项可以选中或不选,且不会出现在选择列表中 default y ---->表示缺省情况是选中2.3 if..endifif ARCH_S5PC100 --->如果ARCH_S5PC100选项选中了,则在endif范围内的选项才会被选 config CPU_S5PC100 bool "选项名" select S5P_EXT_INT select SAMSUNG_DMADEV help Enable S5PC100 CPU support endif举个例子,如果CPU没有选择使用多核CPU,则不会出现CPU个数的选项。2.4 choice多个选项choice --->表示选择列表 prompt "Default I/O scheduler" //主目录名字 default DEFAULT_CFQ //默认CFQ help Select the I/O scheduler which will be used by default for all block devices. config DEFAULT_DEADLINE bool "Deadline" if IOSCHED_DEADLINE=y config DEFAULT_CFQ bool "CFQ" if IOSCHED_CFQ=y config DEFAULT_NOOP bool "No-op" endchoice2.5 menu与menuconfigmenu "Boot options" ----> menu表示该选项是不可选的菜单,其后是在选择列表的菜单名 config USE_OF bool "Flattened Device Tree support" select IRQ_DOMAIN select OF select OF_EARLY_FLATTREE help Include support for flattened device tree machine descriptions. .... endmenu ----> menu菜单结束menu指的是不可编辑的menu,而menuconfig则是带选项的menumenu和choice的区别menu 可以多选 choice 是单项选择题menuconfig的用法menuconfig MODULES ---> menuconfig表示MODULE是一个可选菜单,其选中后是CONFIG_MODULES bool "菜单名" if MODULES ... endif # MODULES说到底,menconfig 就是一个带选项的菜单,在下面需要用bool判断一下,选择成立后,进入if …endif 中间得空间。3.基本使用方法将写好的驱动添加到内核编译选项中1.配置Kconfig在driver目录下新建一个目录test,进入test目录,创建Kconfig文件config TEST bool "Test driver" help this for test!这里定义了一个TEST的句柄,Kconfig可以通过这个句柄来控制Makefile中是否编译,”Test driver”是显示在终端的名称。2.配置Makefile在test目录,新建一个Makefileobj-$(CONFIG_TEST) += test.o意义:obj-$(CONFIG_选项名) += xxx.o /* 当CONFIG_选项名=y时,表示对应目录下的xxx.c将被编译进内核 当CONFIG_选项名=m时对应目录下的xxx.c将被编译成模块*/3.配置上层目录的Makefile与Kconfig在上一层目录的Kconfig中,menu "Device Drivers" source "drivers/test/Kconfig"表示将test文件夹中的Kconfig加入搜寻目录在上一层目录的Makefile中,更改如下obj-y += irqchip/ obj-y += bus/ obj-y += test/ #新添加最后,运行make menuconfig,可进行配置,保存后生成.config文件。
-
字符设备驱动 1.Linux字符设备驱动结构1.1 cdev结构体在Linux内核中,使用cdev结构体描述一个字符设备,cdev结构体定义如下,struct cdev { struct kobject kobj; /* 内嵌的kobject对象 */ struct module *owner; /* 所属模块 */ struct file_operations *ops; /* 文件操作结构体 */ struct list_head list; dev_t dev; /* 设备号 */ unsigned int count; }cdev结构体的dev_t成员定义了设备号,为32位,其中12位为主设备号,20位为次设备号。使用下列宏可以从dev_t获得主设备号和次设备号;MAJOR(dev_t dev) MINOR(dev_t dev)使用下列宏可以通过主设备号和次设备号生成dev_t:MKDEV(int major, int minor)Linux内核提供了一组函数以用于操作cdev结构体:/* 初始化cdev成员,并建立cdev和file_operations之间的连接*/ void cdev_init(struct cdev *, struct file_operations *); /* 动态申请一个cdev内存 */ struct cdev *cdev_alloc(void); /* */ void cdev_put(struct cdev *p); /* 向系统添加一个cdev,完成字符设备的注册。对cdev_add()的调用通常发生在字符设备驱动模块加载函数中 */ int cdev_add(struct cdev *, dev_t, unsigned); /* 对cdev_del()函数的调用通常发生在字符设备驱动模块卸载函数中 */ void cdev_del(struct cdev *);1.2 分配和释放设备号在调用cdev_add()函数向系统注册字符设备之前,应首先调用register_chrdev_region()或alloc_chrdev_region()函数向系统申请设备号,相应地,在调用cdev_del()函数从系统注销字符设备之后,unregister_chrdev_region()会被调用以释放原先申请的设备号,函数原型为:/* 已知起始设备的设备号的情况,from:要分配设备编号范围的初始值(次设备号常设为0),count为连续编号范围,name为编号相关联的设备名称 */ int register_chrdev_region(dev-t from, unsigned count, const char *name); /* 设备号未知,向系统动态申请未被占用的设备号的情况,函数调用成功后,会把得到的设备号放入第一个参数dev中,其优点是自动避开设备号重复的冲突 */ int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count, const char *name); /* 在调用cdev_del()函数从系统注销字符设备之后,unregister_chrdev_region()被调用以释放原先申请的设备号 */ void unregister_chrdev_region(dev_t from, unsigned count);1.3 file_operations结构体file_operations结构体中的成员函数是字符设备驱动程序设计的主体内容,这些函数实际会在应用程序进行Linux的open()、write()、read()、close()等系统调用时最终被内核调用。file_operations结构体的主要成员:llseek()函数用来修改一个文件的当前读写位置,并将新位置返回,在出错时,这个函数返回一个负值。read()函数用来从设备中读取数据,成功时函数返回读取的字节数,出错时返回一个负值。write()函数向设备发送数据,成功时该函数返回写入的字节数。read()和write()如果返回0,则暗示end-of-file(EOF)unlocked_ioctl()提供设备相关控制命令的实现(既不是读操作,也不是写操作),当调用成功时,返回给调用程序一个非负值。mmap()函数将设备内存映射到进程的虚拟地址空间中,如果设备驱动未实现此函数,用户进行mmap()系统调用时将获得-ENODEV返回值。当用户空间调用Linux API函数open()打开设备文件时,设备驱动的open()函数最终被调用。驱动程序可以不实现这个函数,在这种情况下,设备的打开操作永远成功。与open()对应的是release()函数。poll()函数一般用于询问设备是否可被非阻塞地立即读写。当询问的条件未触发时,用户空间进行select()和poll()系统调用将引起进程的阻塞。aio_read()和aio_write()函数分别对与文件描述符对应的设备进行异步读、写操作。1.4 字符设备驱动的组成1.4.1 字符设备驱动模块加载与卸载函数在字符设备驱动模块加载函数中应该实现设备号的申请和cdev的注册,而在卸载函数中应实现设备号的释放和cdev的注销。Linux内核的编码习惯是为设备定义一个设备相关的结构体,该结构体包含设备所涉及的cdev、私有数据及锁等信息。1.4.2 字符设备驱动的file_operations结构体中成员函数file_operations结构体中的成员函数是字符设备驱动与内核虚拟文件系统的结口,是用户空间对Linux进行系统调用最终的落实者。大多数字符设备会实现read()、write()和ioctl()函数。由于用户空间不能直接访问内核空间的内存,因此借助了函数copy_from_user()完成用户空间缓冲区到内核空间的复制,以及copy_to_user()完成内核空间到用户空间缓冲区的复制。以上函数均返回不能被复制的字节数,因此,如果完全复制成功,返回值为0.如果复制失败,则返回负值。如果复制的内存是简单类型,如char、int、long等,则可以使用简单的put_user()和get_user()
-
IDR机制分析 1.IDR简述idr在linux内核中指的就是整数ID管理机制,从本质上来说,这就是一种将整数ID号和特定指针关联在一起的机制。这个机制最早是在2003年2月加入内核的,当时是作为POSIX定时器的一个补丁。现在,在内核的很多地方都可以找到idr的身影。idr机制适用在那些需要把某个整数和特定指针关联在一起的地方。举个例子,在I2C总线中,每个设备都有自己的地址,要想在总线上找到特定的设备,就必须要先发送该设备的地址。如果我们的PC是一个I2C总线上的主节点,那么要访问总线上的其他设备,首先要知道他们的ID号,同时要在pc的驱动程序中建立一个用于描述该设备的结构体。此时,问题来了,我们怎么才能将这个设备的ID号和他的设备结构体联系起来呢?最简单的方法当然是通过数组进行索引,但如果ID号的范围很大(比如32位的ID号),则用数组索引显然不可能;第二种方法是用链表,但如果网络中实际存在的设备较多,则链表的查询效率会很低。遇到这种清况,我们就可以采用idr机制,该机制内部采用radix树实现,可以很方便地将整数和指针关联起来,并且具有很高的搜索效率。2.idr源码分析idr的源码位于linux/idr.h文件,本文使用linux5.5.4内核代码2.1 idr结构体代码定义与初始化struct idr { struct radix_tree_root idr_rt; unsigned int idr_base; unsigned int idr_next; };其中,radix_tree_root定义为define radix_tree_root xarrayidr的初始化// 静态初始化 #define IDR_INIT(name) IDR_INIT_BASE(name, 0) // 动态初始化 static inline void idr_init(struct idr *idr);2.2 为idr分配内存void idr_preload(gfp_t gfp_mask);2.3 分配id号和指针关联int idr_alloc(struct idr , void ptr, int start, int end, gfp_t);2.4 通过id号搜索对应的指针void idr_find(const struct idr , unsigned long id);2.5 删除idvoid idr_remove(struct idr , unsigned long id);3.IDR使用